CLI Reference
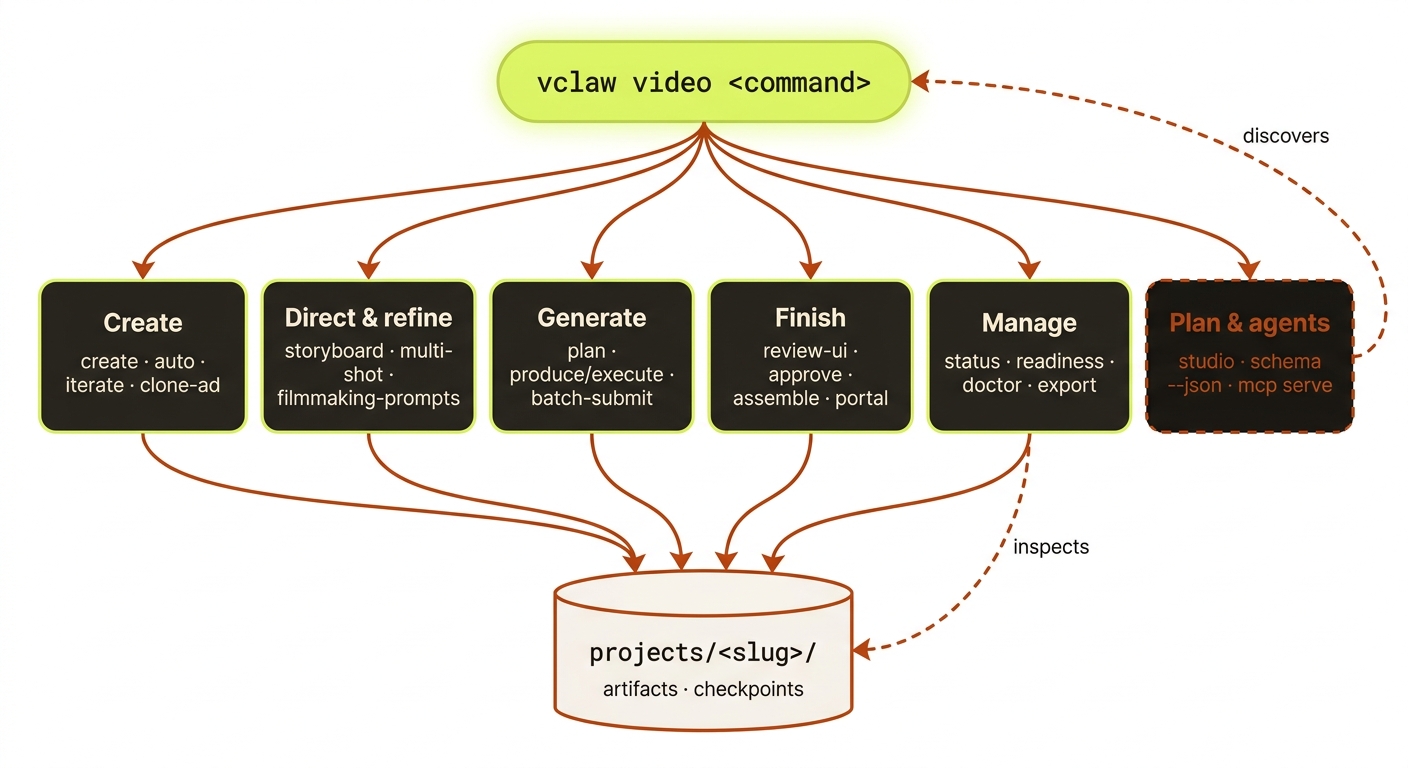
Diagram source (live Mermaid)
Agent-friendly surface (v3)
These four properties hold across every vclaw subcommand. They are the contract external agents (Claude Code / Codex / Antigravity / Cursor) can rely on.
1. JSON on non-TTY
When stdout is not a TTY (i.e., piped to another command or captured by an agent), every subcommand writes JSON to stdout. Human-readable formatting is reserved for interactive TTY use. Progress chatter (spinners, status updates) always goes to stderr.
# TTY (human): pretty-printed
vclaw video providers
# Non-TTY (agent / pipe): newline-terminated JSON
vclaw video providers | jq '.routes[].routeId'2. Exit-code taxonomy
| Code | Name | Meaning |
|---|---|---|
| 0 | SUCCESS | Command completed without errors. |
| 1 | USER_ERROR | Bad input — invalid flag, missing argument, validation failure. Retrying with the same input will fail the same way. |
| 2 | SYSTEM_ERROR | Environmental failure — provider down, disk full, missing env var. Retry may succeed. |
| 3 | GATE | Gated by an approval / readiness check (e.g., director storyboard.md not approved yet). The command CAN succeed once the gate clears. |
Agents decide retry strategy from the exit code. Code 1 means "fix the input and retry"; code 2 means "investigate the system and try later"; code 3 means "do the gate-clearing work first, then retry."
3. Stable error codes
On any non-zero exit, stdout contains a JSON envelope with a stable string code field. The full catalog lives at schemas/video/errors.json and the TS source-of-truth is src/video/errors.ts ALL_ERROR_CODES.
{
"code": "project_not_found",
"message": "No workspace at projects/foo/",
"details": { "slug": "foo" }
}Codes are stable — once shipped, they never change name. New codes get added; old ones may get a deprecation note but the string stays working for old agents.
4. Single-call discovery: vclaw schema --json
Returns the full v3 contract in one call:
version: the v3 release this dump comes fromcommands: array of{name, usage, flags, aliases?}exitCodes: the 0/1/2/3 taxonomyerrorCodes: the full ALL_ERROR_CODES listartifactSchemas: everyschemas/video/artifacts/*.schema.jsonembedded by name
Agents should call this once on first contact, then drive the CLI from the dump without further introspection. Cheaper than per-command --help parsing.
vclaw schema --json | jq '.commands | map(.name)'Noun-verb command conventions
v3 prefers noun-verb command shape (vclaw video character list) over hyphenated forms (vclaw video character-list). Both work — every kebab form has a noun-verb alias registered. The canonical name in vclaw schema --json is the kebab form for now (backwards compat); v3.1 will switch the canonical form and alias the kebab.
See vclaw schema --json | jq '.commands[] | {name, aliases}' for the complete list.
vclaw veo * subcommands keep the Bun CLI's colon-separated form (useapi:accounts list, not useapi accounts list). This matches the underlying bun run flow.ts surface. Aliasing the colon to a space would create confusion for users with existing scripts.
Studio Planner
vclaw studio is the human-friendly planning front door. It maps goals such as presenter video, UGC campaign, music video, copy-reference, review, and publish to deterministic CLI commands.
vclaw studio [--dry-run] [--goal <goal>] [--project <slug>] [--intent <text>] [--input <path-or-url>] [--client <name>] [--duration <seconds>] [--write-session] [--execute] [--confirm-spend] [--auto-approve-storyboard] [--from-step <id>]Supported goals:
create-videocopy-referencepresenter-videomusic-videougc-campaignexisting-projectreview-regeneratepublish-deliver
Studio is plan-only by default: it returns a command plan and optional studio-session.json artifact, but runs nothing.
Add --execute to run the emitted plan — Studio shells out to the same vclaw video … commands (it does not re-implement orchestration). Three modes, chosen at run time:
--execute— dry: free steps + spend steps with--dry-run; a spend subcommand lacking--dry-runis refused (blocked-spend). Spends nothing.--execute --confirm-spend— real render, human-gated: promotes the dry spend steps to real (strips--dry-run); the render still needs the storyboard approved out-of-band (the runner stripsVIDEOCLAW_APPROVE_STORYBOARD).--execute --confirm-spend --auto-approve-storyboard— unattended render: also setsVIDEOCLAW_APPROVE_STORYBOARDso one command runs through the real render with no human checkpoint.
It fails fast (a blocked/failed step stops with no partial spend) and --from-step <id> resumes after an approval. The result is reported under an execution block (mode, per-step status, stopReason, a dry-mode hint). See docs/STUDIO.md.
Veo (Bun bridge)
The vclaw veo * subcommand family bridges to the Bun-based vclaw-cli/flow.ts for Google Flow access via Puppeteer. The Bun runtime is required (install via curl -fsSL https://bun.sh/install | bash).
Standard verbs
| Command | Purpose |
|---|---|
vclaw veo status [batchId] | Show batch status. |
vclaw veo list | List all batches. |
vclaw veo history [--limit <n>] | Recent job history. |
vclaw veo resume [batchId] | Resume a paused batch. |
vclaw veo reset | Reset failed jobs to pending. |
vclaw veo cancel | Cancel current batch. |
UseAPI verbs
| Command | Purpose |
|---|---|
vclaw veo useapi:accounts list|add | Manage useapi.net accounts. |
vclaw veo useapi:captcha list | --provider <name> --key <key> | CAPTCHA providers. |
vclaw veo useapi:health | Account health + history. |
vclaw veo useapi:image --image-prompt "..." | Generate images. |
vclaw veo useapi:image:upscale --media-id <id> --resolution 2k|4k | Upscale images. |
vclaw veo useapi:gif --media-id <id> --output-file <path> | Video → GIF (free). |
vclaw veo useapi:upscale --media-id <id> --resolution 1080p|4k | Upscale videos. |
See vclaw schema --json | jq '.commands[] | select(.name | startswith("veo "))' for the canonical list.
The legacy standalone form bun run vclaw-cli/flow.ts <verb> still works in v3.0 but is being deprecated. Use vclaw veo * going forward.
Project lifecycle
vclaw video init <slug> [--root <path>] [--mode storyboard|director]
vclaw video create "<intent>" [--project <slug>] [--root <path>] [--production-mode storyboard|director] [--title <title>] [--scenes <count>] [--style <preset>] [--color-grading <preset>] [--platform <name>] [--gb-character <Name:ID> ...] [--import-library-characters] [--auto-create-characters <json-path>] [--api-url <url>] [--aspect-ratio 16:9|9:16|1:1] [--quality fast|quality] [--resolution 720p|1080p] [--audio on|off] [--outputs 1-4] [--apply-content-fixes] [--execute] [--dry-run]
vclaw video auto "<intent>" [...same flags as create]
vclaw video iterate "<intent>" [...same flags as create]
vclaw video run-pipeline "<intent>" [...same flags as create]
vclaw video brief --project <slug> --title <title> --intent <intent> [--root <path>] [--mode storyboard|director] [--platform <name>] [--aspect-ratio 16:9|9:16|1:1] [--quality fast|quality] [--resolution 720p|1080p] [--audio on|off] [--outputs 1-4]
vclaw video storyboard-template-list
vclaw video storyboard-template-show --name <template-id>
vclaw video storyboard --project <slug> (--scene <text> [--scene <text> ...] | --template <template-id> [--environment <text>] [--character-a <name>] [--character-b <name>]) [--scene-character <sceneIndex:name> ...] [--root <path>]
vclaw video assets --project <slug> --asset <kind:path[:sceneIndex][:backend]> [--asset ...] [--root <path>]
vclaw video review-ui --project <slug> [--root <path>] [--host <host>] [--port <port>] [--ui-path <path>] [--dry-run]
vclaw video review-autopilot --project <slug> [--root <path>] [--template <template-id>] [--character <name>] [--run-id <id>]
vclaw video storyboard-grid --project <slug> [--root <path>] [--output <path>] [--width <px>] [--height <px>] [--dry-run]
vclaw video portal --project <slug> [--root <path>] [--client <name>] [--run <id>] [--surface edit|review|client-review|preview|compare|run|index]
vclaw video portal-index [--root <path>] [--client <name>] [--output <path>]
vclaw video publish-preview --project <slug> --client <name> --bucket <bucket> [--root <path>] [--run <id>] [--surface edit|review|client-review|preview|compare|run|index] [--public-base-url <url>] [--wrangler-bin <path>] [--dry-run]
vclaw video publish-portal-index --bucket <bucket> [--root <path>] [--client <name>] [--public-base-url <url>] [--wrangler-bin <path>] [--dry-run]
vclaw video review --project <slug> --verdict pass|retry|fail [--finding <text> ...] [--root <path>]
vclaw video publish --project <slug> --status ready|published|blocked [--final-output <path>] [--note <text> ...] [--root <path>]For production image-to-video handoff, prefer review-ui or review-autopilot. The simple review --verdict pass path is for projects that already have equivalent review evidence outside the browser station. Publishing remains blocked unless the saved review-report.json has verdict: "pass" and metrics.publishReady: true.
Preview review and delivery portal
The preview portal is the standardized static HTML layer for generated video projects. It replaces one-off preview.html/review.html variants with repeatable surfaces:
Portal rendering reads template or previewTemplate from project.json and uses the built-in registry for music-video, story-film, documentary, product-ad, sports-recap, and generic-video labels/section ordering. It also reads project-scoped image entries from artifacts/asset-manifest.json and renders them as generation inputs; Seedance-backed images appear under Seedance Input Frames for music-video projects so reviewers can inspect the exact start/upscaled frame being sent to Seedance 2.
| Command | Output |
|---|---|
vclaw video portal --project <slug> | Writes review.html, preview.html, and the live run.html dashboard in the project directory. |
vclaw video portal --project <slug> --surface run | Writes only run.html — the live run dashboard (per-generation status badges + diff-vs-contract alarm + playable in-progress clips + event log, auto-refreshing). |
vclaw video portal --project <slug> --surface compare | Writes compare.html for version/run comparison. |
vclaw video portal-index | Writes projects/index.html across all projects. |
vclaw video portal-index --client <name> | Writes projects/clients/<client>/index.html for that client only. |
vclaw video publish-preview --dry-run ... | Prints the Cloudflare R2 upload plan without side effects. |
vclaw video publish-preview ... | Uploads referenced files with wrangler r2 object put and records a publish audit event. |
vclaw video publish-portal-index --client <name> ... | Uploads a client index to clients/<client>/index.html with links into each uploaded run folder. |
Live run dashboard (--surface run)
run.html is a first-class portal surface and the live operations view for a render: one card per generation (storyboard scene) with a STATUS badge (done / rendering / pending / failed), the provider job id and any error, the input keyframe, a playable in-progress clip (outputs/scene-N.mp4), the exact submit prompt + contract, a spend estimate chip, an event log (events/events.jsonl), per-card copy-command buttons, and a Show › Episode header from show-bible.json. It paints a RED diff-vs-contract alarm when the submitted payload diverged from the current contract (the @tag-hijacks-the- references class of bug), backed by the frozen artifacts/run-contract.json snapshot that produce/execute persists at submit time. The page auto-refreshes via <meta http-equiv="refresh">, and run.html is regenerated automatically on every produce/execute and execute-status poll (it is part of the default vclaw video portal surface set). Set VCLAW_NO_RUN_SURFACE=1 to skip the automatic regeneration.
Example local generation:
vclaw video portal \
--project 2026-05-27_dhuaan-music-video \
--root /path/to/video-workspace \
--client "Acme Studios" \
--run run-002Example publish dry-run:
vclaw video publish-preview \
--project 2026-05-27_dhuaan-music-video \
--root /path/to/video-workspace \
--client "Acme Studios" \
--run run-002 \
--surface preview \
--bucket videoclaw-reviews \
--public-base-url https://reviews.example.com \
--dry-runThe publish plan includes the HTML file plus local src/href references, content types, R2 keys, SHA-256 hashes, and public URLs when a base URL is provided. Running without --dry-run requires wrangler to be installed and authenticated. --wrangler-bin can point to a specific Wrangler executable when running from automation.
Project surfaces publish under clients/<client>/<project>/runs/<run>/<surface>.html. Published client indexes link to those run folders, so a client with six generations can open clients/<client>/index.html and choose among all six project/run previews.
vclaw video create is the clean-room front door for the legacy “one command to start a project” mental model. In its current form it:
- initializes the project when needed
- writes canonical
briefandstoryboardartifacts - scaffolds storyboard-seed assets for execution planning
- records Go Bananas character bindings as project character profiles
- can import exact-name Go Bananas matches from the story intent when
--import-library-charactersis present - can auto-create missing Go Bananas characters from a JSON seed file via
--auto-create-characters <json-path> - carries execution-profile overrides (
aspect-ratio,quality,resolution,audio,outputs) into the canonical brief and status surfaces - generates
storyboard.mdautomatically fordirectormode - optionally hands off to the existing
executepath when--executeis present
For director mode, this means the first-run path now supports the same storyboard-first approval pattern as the older workflow surface, while still writing canonical clean-room artifacts underneath.
vclaw video auto, vclaw video iterate, and vclaw video run-pipeline are thin creator-mode drivers over video create (same flag surface) with opinionated defaults:
vclaw video auto "<intent>" [...]— defaults--production-mode directorwhen neither--modenor--production-modeis passed; otherwise identical tocreate.vclaw video iterate "<intent>" [...]— defaultsdirectormode AND force-appends--execute, so it re-generates and immediately runs the project in one shot.vclaw video run-pipeline "<intent>" [...]— the full create→execute pipeline driver: defaultsdirectormode and--execute;--dry-runis supported to plan the run without submitting.
Story bible (continuity reference)
Every storyboard-producing command now also emits a deterministic continuity bible — projects/<slug>/artifacts/story-bible.json (schema schemas/video/artifacts/story-bible.schema.json, schemaVersion: 1). It is derived from the canonical brief + storyboard + character profiles (characters/characters.json); it spends no credits and calls no providers. The commands that write it are video create, video storyboard, video clone-execute, video storyboard-from-clone, video storyboard-review, and video director-preflight --apply-content-fixes (the bible is regenerated after director content-fixes are applied, so it always reflects the corrected storyboard).
The artifact gives downstream generation one machine-readable reference so scenes and regenerations stay consistent — cast (characters[] with referenceAssets), settings[], props[], a per-scene timeline (scenes[] with startSeconds/endSeconds/durationSeconds, charactersPresent, visualPrompt/motionPrompt/diegeticAudio, and continuityNotes[]), and a rolled-up timeline.
It is recorded in the storyboard checkpoint under artifacts['story-bible'], carried on the artifact.storyboard.written event payload as storyBiblePath, and surfaced as storyBiblePath in the command's JSON output. doctor-project validates it (added to the canonical-artifacts list, plus a malformed-JSON check on artifacts/story-bible.json).
End-to-end smoke (create → storyboard continuity + content-fix propagation, image-only path):
npm run smoke:story-bible-imageAnalysis and templates
vclaw video analyze --project <slug> --source <path-or-url> [--title <title>] [--beat <text> ...] [--keep <text> ...] [--change <text> ...] [--var <text> ...] [--auto]
vclaw video analyze-template --project <slug> --source <path-or-url> [options] [--auto]
vclaw video prompt-lib-list
vclaw video prompt-lib-show --name <reference-name> [--root <path>]
vclaw video template-create --project <slug> --name <template-name> [--root <path>]
vclaw video template-save --project <slug> --name <template-name> [--root <path>]
vclaw video template-list [--root <path>]
vclaw video template-show --name <template-name> [--root <path>]
vclaw video template-validate --name <template-name> [--root <path>]
vclaw video clone-ad --template <template-name> --project <slug> --intent <text> [--root <path>] [--mode storyboard|director] [--platform <name>] [--aspect-ratio 16:9|9:16|1:1] [--quality fast|quality] [--resolution 720p|1080p] [--audio on|off] [--outputs 1-4] [--dry-run]
vclaw video clone-plan --template <template-name> --project <slug> --intent <text> [--root <path>]
vclaw video clone-init --template <template-name> --project <slug> --intent <text> [--root <path>] [--mode storyboard|director] [--platform <name>] [--aspect-ratio 16:9|9:16|1:1] [--quality fast|quality] [--resolution 720p|1080p] [--audio on|off] [--outputs 1-4]
vclaw video storyboard-from-clone --project <slug> [--root <path>] [--mode storyboard|director]
vclaw video clone-execute --template <template-name> --project <slug> --intent <text> [--root <path>] [--mode storyboard|director] [--platform <name>] [--aspect-ratio 16:9|9:16|1:1] [--quality fast|quality] [--resolution 720p|1080p] [--audio on|off] [--outputs 1-4] [--dry-run]When --auto is present on analyze / analyze-template, the clean-room repo uses the Gemini HTTP path to fill the analyze artifact automatically. It reads keys from GEMINI_API_KEYS, GOOGLE_API_KEYS, or GOOGLE_API_KEY, and you can override the endpoint with VCLAW_GEMINI_API_ENDPOINT. When --source is a readable local video file, --auto now samples ~6 JPEG frames spread evenly across the whole clip (a frame every duration / 6 seconds via ffmpeg's fps filter — the clip duration is probed when not supplied; overridable with VCLAW_FFMPEG_BIN) and sends them to Gemini so the analysis is grounded in the actual footage start-to-end, not just the opening ~20s. URL sources, directory paths, and any frame extraction that fails stay metadata-only and fall back to text-only analysis (clips whose duration cannot be determined fall back to ffmpeg's head-clustered thumbnail sampling).
Analyze artifacts can now carry optional clone-planning fields:
styleLayersbeatCompressiontechnicalNotesdialogueNotes
Saved templates preserve those fields and clone plans copy them forward with a workflowChecklist so operators can keep the reusable mechanism while replacing brand, product, audience, proof, and offer details.
Project management
vclaw video set-meta --project <slug> [--root <path>] [--owner <name>] [--priority low|medium|high|critical] [--due YYYY-MM-DD] [--tag <value> ...] [--blocked-by <slug> ...] [--blocked-reason <text>]
vclaw video set-execution-profile --project <slug> [--root <path>] [--aspect-ratio 16:9|9:16|1:1] [--quality fast|quality] [--resolution 720p|1080p] [--audio on|off] [--outputs 1-4]
vclaw video character-add --project <slug> --name <name> [--gb-id <id>] [--description <text>] [--ref <path> ...] [--note <text> ...] [--root <path>]
vclaw video character-auto-create --project <slug> --input <json-path> [--root <path>] [--api-url <url>] [--no-sheet] [--sheet-preset <id>] [--dry-run]
vclaw video environment-auto-create --project <slug> --input <json-path> [--root <path>] [--api-url <url>] [--dry-run]
vclaw video character-import-library --project <slug> --intent "<text>" [--root <path>] [--api-url <url>]
vclaw video character-list --project <slug> [--root <path>]
vclaw video character-show --project <slug> --name <name> [--root <path>]
vclaw video character-consistency --project <slug> [--root <path>]
vclaw video find-library --intent "<text>" [--api-url <url>]
vclaw video library find --intent "<text>" [--api-url <url>]
vclaw video library clean [--ids <csv>] [--name-regex <pattern>] [--bloated] [--max-prompt-chars <n>] [--dry-run] [--yes]
vclaw video library clean --patch <id> --base-prompt <text> [--dry-run]
vclaw video status --project <slug> [--root <path>] [--mode storyboard|director]
vclaw video readiness --project <slug> [--root <path>] [--mode storyboard|director]
vclaw video plan --project <slug> [--root <path>] [--mode storyboard|director]
vclaw video execution-plan --project <slug> [--root <path>] [--mode storyboard|director]
vclaw video produce --project <slug> [--root <path>] [--mode storyboard|director] [--scene <n> ...] [--dry-run] [--continuity-feedback] [--auto-chain] [--chain-fallback]
vclaw video execute --project <slug> [--root <path>] [--mode storyboard|director] [--scene <n> ...] [--dry-run] [--continuity-feedback] [--auto-chain] [--chain-fallback]
vclaw video execute-status --project <slug> [--root <path>] [--mode storyboard|director]
vclaw video execute-cancel --project <slug> [--root <path>] [--mode storyboard|director]
vclaw video assemble --project <slug> [--root <path>] [--brand-profile <path>] [--from-clips] [--dry-run]
vclaw video soundtrack --project <slug> (--prompt "<text>" [--duration <seconds>] [--backends suno,lyria,lyria3,flowmusic] [--lyrics "<[Verse]…>"] [--instrumental] [--dry-run] [--confirm-spend] | --select <backendId>) [--root <path>]
vclaw video narrate --project <slug> (--text "<script>" | --text-file <path>) [--voice <name>] [--backend gemini-tts|elevenlabs-tts] [--video-duration-ms <ms>] [--dry-run] [--confirm-spend] [--root <path>]
vclaw video dialogue --project <slug> --turns "Name: line || Name2: line2" [--voice <name>] [--backend gemini-tts|elevenlabs-tts] [--dry-run] [--confirm-spend] [--root <path>]
vclaw video sfx --project <slug> --prompt "<text>" [--duration <seconds>] [--prompt-influence <0..1>] [--backend elevenlabs-sfx] [--dry-run] [--confirm-spend] [--root <path>]
vclaw video gen-image --project <slug> --prompt "<text>" --kind prop|screen|overlay [--backend gobananas|openai|flow] [--scene <i>] [--out <path>] [--aspect <ratio>] [--model <id>] [--ref <path|mediaGenerationId>]... [--character <name|ref>]... [--count <1-4>] [--seed <n>] [--dry-run] [--root <path>]
vclaw video overlay --input <video> --output <path> (--graphic <png> | --alert "<text>" | --lower-third "<text>") [--position <pos>] [--start <s>] [--end <s>] [--fade-in <s>] [--fade-out <s>] [--opacity <0..1>] [--pulse-hz <n>] [--font-size <n>] [--color <c>] [--dry-run]
vclaw video review-ui --project <slug> [--root <path>] [--host <host>] [--port <port>] [--ui-path <path>] [--dry-run]
vclaw video review-autopilot --project <slug> [--root <path>] [--template <template-id>] [--character <name>] [--run-id <id>]
vclaw video artifact-history --project <slug> --artifact <name> [--root <path>]
vclaw video doctor-project --project <slug> [--root <path>] [--mode storyboard|director]
vclaw video verify-env [--root <path>] [--workspace-root <path>]vclaw video verify-env is the environment readiness doctor. It prints a JSON environment report (provider keys, runtimes) from buildVideoEnvironmentReport; it is read-only, needs no project, and resolves its workspace root from --workspace-root, then --root, then the current directory.
Primary lifecycle names are now plan and produce. execution-plan and execute remain supported as compatibility aliases over the same handlers.
--continuity-feedback (opt-in, default off) turns on the PHASE-3 continuity loop. It only affects scenes that already carry a chain-from-prev seed (set via the scene-selection chainFromPrev flag in candidate mode). For each such scene it (1) enriches task.prompt with a concise Continuity: <cues> clause and (2) re-pastes the project's full cast/setting/prop descriptor block from the story-bible artifact verbatim (StoryCraft anti-drift). When the prior scene's seed is an on-disk image and a Gemini key (GEMINI_API_KEYS / GOOGLE_API_KEY) is configured, the cues are extracted by a single Gemini gemini-2.0-flash call on that image; otherwise (video seed, no key, or any Gemini failure) it falls back to the deterministic story-bible descriptors. The re-paste is idempotent. Omitting the flag is byte-identical to today — no Gemini call and no prompt mutation.
--auto-chain (opt-in, default off) renders the whole storyboard as a continuity chain in one command. Scene 0 renders first; then every later scene is automatically seeded from the previous scene's selected output video (chainFromPrev) with continuity prompt-augmentation bundled in (it implies --continuity-feedback). The previous scene's produced candidate is auto-selected — no manual reroll-scene per scene. Output is a JSON auto-chain report: scenes[] (each with chainedFrom + selectedCandidateId) and stoppedAt (the scene index where it halted, or null). It is resumable — re-running skips scenes that already have a selection — and fail-fast: a scene that yields no usable candidate halts the chain rather than breaking continuity silently. In director mode the storyboard-approval gate still applies before the first render; for an unattended chain set VIDEOCLAW_APPROVE_STORYBOARD=1 so the per-scene gate stays open through the loop. --scene a b c restricts and orders the chained subset. It is incompatible with --dry-run (chaining needs each scene's real rendered output to seed the next) and is rejected with invalid_flag_value rather than silently rendering for real. Because the seedance reference assembly now merges identity + continuity, a chained scene keeps BOTH its character Asset:// refs and the keyframe video.
--chain-fallback (opt-in) makes the chain self-heal instead of fail-fast. A chained scene can produce no usable candidate when the provider rejects its video reference — e.g. Seedance's face filter (fail_code 4011 RejectFace) rejects a specific upstream clip as an input reference even though other clips pass. With this flag, such a scene retries down a ladder — chain-from-prev → chain-from-anchor (the first scene) → image-only — instead of stopping the whole chain (stoppedAt). The first rung that yields a candidate wins; image-only drops the video chain seed but still renders from the scene's character/identity references. When a non-default rung is used, the scene's auto-chain report entry carries a fallback label (e.g. chain-from-0, image-only). Default off → byte-identical fail-fast behavior. The explicit chain source is recorded as chainFromSceneIndex on the scene-selection entry.
Chain-seed hosting (seedance-direct). runway/dreamina-useapi upload local references themselves, but seedance-direct rejects local file paths — a reference must be a hosted HTTP(S) URL or an Asset:// URI. So on that route the chain seed (the prior scene's downloaded .mp4) is automatically converted to a hosted last-frame image: ffmpeg extracts the final frame, it is uploaded to Go Bananas (returning a public R2 URL), and that image becomes the scene's keyframe reference (reference_images). This is the proven seedance image-to-video keyframe path; it needs GO_BANANAS_API_KEY and ffmpeg on PATH. A seed that is already a hosted URL / Asset:// URI passes through untouched, and the transform never runs off the seedance route.
@Name asset tagging (in scene prompts)
Write @Youri (or @tokyo-alley) in any scene prompt. At payload assembly the tag is replaced with that character's visual descriptor (never the proper name — names don't survive across generations) and the character's saved reference is auto-wired into that scene, counted against the ≤9 image / ≤3 video / ≤3 audio budget. The reference is the character's Asset:// URI on seedance-direct (and only that — a raw referenceAssets portrait is not wired on seedance, since a local/photoreal portrait both fails submit and trips the real-person filter; the descriptor text still substitutes, so register the character with seedance-register-assets to lock identity); on every other route it falls back to the first referenceAssets image. An unresolved tag (no matching character/asset) is left as the bare word with a stderr warning — it never blocks a render. The @imageN positional binding is reserved (left verbatim). Prompts with no @ tokens are byte-identical to before. @location tags resolve once environment-assets.json exists — generate it with vclaw video environment-auto-create.
vclaw video environment-auto-create
vclaw video environment-auto-create --project <slug> --input <json-path> [--api-url <url>] [--dry-run] — the location half of the Asset-First Principle, mirroring character-auto-create. The --input JSON is an array of { name, description, style? }; for each it generates a seamless empty environment plate (no people) via the Go Bananas /images backend and writes artifacts/environment-assets.json ({ name, description, plateUrl, plateRef } per location). readEnvironmentAssets then feeds those into @location tag resolution — @tokyo-alley in a prompt becomes the plate's descriptor and wires its reference. --dry-run skips all network calls. Needs GO_BANANAS_API_KEY.
vclaw video review-ui starts the local human-in-the-loop review station. It serves the bundled Review UI asset by default, exposes project inventory at /api/review-inventory, and lets the operator save the current decision ledger to projects/<slug>/artifacts/review-ui-ledger.json. Saving also derives reference-board.json, director-seedance-plan.json, storyboard-stills-plan.json, scene-selection.json, gobananas-character-brief.json, post-plan.json, and review-report.json so the next agent has concrete production artifacts rather than a loose UI note. Publish handoff is canonical only when that saved review-report.json has verdict: "pass" and metrics.publishReady: true; stale checkpoints or legacy pass reports without that metric remain review work. Use it when a project needs storyboard, reference, character, motion-plan, or final assembly choices before the next agent step. Use --ui-path <path> only when testing a local replacement UI.
The review station is explicitly aligned to docs/REFERENCE_VIDEO_SEEDANCE_MOTION_DESIGN_WORKFLOW.md. Its director defaults record the expected professional workflow in the saved ledger: script/voiceover first, role-tagged references, still-frame lock, upscaled Seedance inputs, start/end frame chaining, control plus short-variant motion prompts, bridge poses for hard actions, continuity-frame extraction, and post retiming.
vclaw video review --verdict pass remains the simple artifact-stage approval command for projects that were already reviewed outside the browser station. It writes review-report.json with metrics.publishReady: true, so use it only when the operator has equivalent evidence. For director image handoffs, prefer review-ui or review-autopilot; those paths derive publishReady from locked scene candidates, artifact-backed 4K stills, character-match checks, and final assembly approvals.
For the operator-facing step-by-step workflow, see docs/REVIEW_UI_STORYBOARD_WORKFLOW.md.
vclaw video review-autopilot is the non-interactive counterpart for projects that already have storyboard still candidates. It selects and locks the best completed still per scene, creates artifact-backed upscaled handoff candidates from local still assets where possible, fills the final approval checks, and writes the same review-report.json readiness truth as the browser station. It does not submit video generation jobs.
Go Bananas library cleanup
vclaw video library clean is the clean-room port of the legacy character library hygiene tool. It supports:
- listing cleanup candidates by explicit IDs, name regex, or bloated prompt size
- dry-run review before deletion
- prompt patching for a single library character without deleting it
vclaw video find-library and vclaw video library find provide the exact-name intent lookup used by the migrated Director lane. They extract capitalized candidate names from the intent and call the Go Bananas exact=true search path so reuse stays conservative.
Reference sheets
vclaw video reference-sheet-add --project <slug> --type <identity|outfit-material|environment|motion-camera|palette-mood> --name <name> [--id <id>] [--description <text>] [--character-name <name>] [--ref <path>:<role>[:<note>] ...] [--gb-ref <kind>:<id>:<role>[:<note>] ...] [--binding <sceneIndex> ...] [--root <path>]
vclaw video reference-sheet-list --project <slug> [--type <sheet-type>] [--root <path>]
vclaw video reference-sheet-show --project <slug> --id <sheet-id> [--root <path>]
vclaw video reference-sheet-bind --project <slug> --id <sheet-id> --scene <sceneIndex> [--scene <sceneIndex> ...] [--root <path>]
vclaw video reference-sheet-validate --project <slug> [--root <path>]Reference sheets are role-tagged, per-scene-bound references that the readiness, preflight, and ops surfaces treat as first-class state. Every sheet has one of five types, each with a closed role vocabulary:
identity—identity,wardrobe,silhouette,age-referenceoutfit-material—outfit,material,accessory,texture,product-hero,product-variant,product-in-use,packagingenvironment—location,set-dressing,weather,time-of-daymotion-camera—motion-rhythm,camera-behavior,blocking,shot-framingpalette-mood—palette,composition,mood,lighting-reference
--gb-ref accepts the five Go Bananas kinds: character, product, scene, style-preset, and reference-group. The product kind pairs with the extended product-* roles on outfit-material sheets.
Full operator guide: docs/REFERENCE_SHEETS.md.
Scene candidates and selection
vclaw video candidates-list --project <slug> [--scene <sceneIndex>] [--root <path>]
vclaw video candidates-show --project <slug> --candidate-id <id> [--root <path>]
vclaw video storyboard-still-add --project <slug> --scene <sceneIndex> --image-url <url> [--image-id <id>] [--prompt <text>] [--notes <text>] [--root <path>]
vclaw video select-candidate --project <slug> --scene <sceneIndex> --candidate-id <id> [--notes <text>] [--root <path>]
vclaw video select-candidate --project <slug> --auto-select [--ref <imagePath> ...] [--root <path>]
vclaw video reject-candidate --project <slug> --scene <sceneIndex> --candidate-id <id> [--notes <text>] [--root <path>]
vclaw video reroll-scene --project <slug> --scene <sceneIndex> [--chain-from-prev on|off] [--root <path>]
vclaw video chain-from --project <slug> --scene <sceneIndex> --from <sourceSceneIndex> [--root <path>]
vclaw video unchain --project <slug> --scene <sceneIndex> [--root <path>]
vclaw video candidates-migrate-from-assets --project <slug> [--dry-run] [--root <path>]select-candidate --auto-select is an opt-in LLM-as-judge pass: it reads every scene's candidates, asks Gemini (via the existing GEMINI_API_KEYS pool) to pick the best candidate per scene — conditioned on each candidate's intended prompt, its first image output, and any --ref <imagePath> shared reference images — then applies the pick through the same selectCandidate path a human uses and re-derives the asset-manifest. It is defensive: any scene the judge can't parse or that names an unknown candidate id is left for human selection (reported in the JSON leftToHuman array and on stderr), never failing the batch. Without --auto-select the command's behavior is unchanged (single --scene/--candidate-id human pick).
Scene candidates are the output-layer counterpart to reference sheets. The execute runtime writes every generated take into projects/<slug>/artifacts/scene-candidates.json (append-only) and records operator selection, rejections, pending ids, reroll state, and chain-from-prev into projects/<slug>/artifacts/scene-selection.json (mutable).
storyboard-still-add records generated storyboard still images, such as Go Bananas still outputs, into the same scene-candidate artifact with kind: image. This lets the image/storyboard review loop reuse the existing candidate-selection commands before any video generation happens.
produce and execute also accept one or more --scene <sceneIndex> flags for partial reruns: only the listed scenes get a new generation round, every other scene stays on its currently-selected candidate.
chain-from is v1-limited to chain-from-prev, so --from must equal --scene - 1. Any other source returns chain-from-unsupported.
Full operator guide: docs/SCENE_CANDIDATES.md.
Director approval gate
For director mode, vclaw video produce and vclaw video execute now export projects/<slug>/storyboard.md and block before provider submission unless VIDEOCLAW_APPROVE_STORYBOARD=1 is present in the environment. This preserves the legacy two-step storyboard-review flow without requiring the long smoke path.
vclaw video approve --project <slug> [--root <path>] [--mode storyboard|director] [--dry-run] is the one-shot way to clear that gate and run execution. It requires --project, defaults --mode director, and runs the execution with VIDEOCLAW_APPROVE_STORYBOARD=1 injected internally — so it approves the storyboard.md gate and submits in a single command. --dry-run plans the run without submitting.
When a live job is already in flight, vclaw video execute-cancel attempts to cancel it through the configured adapter surface and records the cancellation into the project execution report and event timeline.
At the moment, the built-in native cancel path exists for seedance-direct. Other routes may return an explicit unsupported cancellation result rather than silently pretending the job was cancelled.
That review file now includes a character-binding table for referenced scene characters, including any stored Go Bananas ids and reference assets.
Assemble stage
vclaw video assemble --project <slug> runs the post-execution assembly pipeline in order: (optional) PDF slide extraction, (optional) branded title card, per-slide animation, per-scene TTS narration, (optional) background-music bed, and the final FFmpeg stitch — then advisory QA (dialogue/narration/image filter) whose findings land in the report warnings. It writes a typed assemble-report.json artifact (schema: schemas/video/artifacts/assemble-report.schema.json).
--dry-run plans the entire pipeline (every FFmpeg command + provider call, recorded into the manifest and events) WITHOUT executing anything or needing ffmpeg or any API key — this is the agent-safe planning surface. --brand-profile <path> supplies the presenter knobs (voice, intro/outro segments, optional deck/music/ title-card config). Real (non-dry-run) assembly spawns FFmpeg and calls the TTS and music providers; verifying the rendered MP4 looks/sounds correct is a human integration checkpoint.
--from-clips switches the body-segment source from animated slides to the per-scene rendered clips vclaw video execute wrote to outputs/scene-<i>.mp4, concatenating a finished clip-based production into one MP4. Each clip's native audio (incl. omni-flash voice) is kept (no TTS narration); the optional music bed is mixed under it; dialogue/SFX auto-layers are not applied. Title card, intro/outro, and per-scene color grade still apply. See docs/ASSEMBLE.md.
Slide-animation styles
vclaw video animation-styles [--style <id>] lists the slide-animation styles from the shared registry (src/video/assemble/animation-styles.json), or prints one style's full Veo motion prompt with --style <id>. Read-only and free.
The styles drive the animated-slide path: each slide becomes a subtle F2V motion loop (camera static, ~80–90% of the frame still) instead of a static hold. There are 11 — broadcast (default), tabloid, minimal, comic, indian-tv, neon-esports, cinematic-film, gold-luxe, retro-vhs, stadium-live, chalkboard. The registry is the single source of truth: this CLI/TS layer and the Python generator (skills/video-replicator/scripts/bunty_animate_slides.py, --style <id>, ~10 Veo credits/slide → stitch_bunty.py --animated) both read the same JSON, so adding a style is a one-file change. Motion prompts are kept clear of content-filter HIGH_RISK_VOCAB (a test enforces this).
Spend gate (paid audio commands).
soundtrack(generate path),narrate,dialogue, andsfxcall paid providers. Invoked directly without--dry-run, they refuse with thespend_confirmation_requiredgate unless you pass--confirm-spendto authorize the spend;--dry-runalways previews offline (no keys/network). Orchestratedstudio --executeruns are gated separately by the fail-closed FREE allow-list.
Soundtrack A/B (vclaw video soundtrack)
vclaw video soundtrack --project <slug> --prompt "<text>" generates one soundtrack candidate per available music backend (the audio-platform registry — suno via KIE_API_KEY, lyria via Vertex creds, lyria3 via a Gemini key, flowmusic via USEAPI_API_TOKEN) and writes each to projects/<slug>/artifacts/audio/soundtrack-<backendId>.mp3, alongside a typed soundtrack.json artifact (schema: schemas/video/artifacts/soundtrack.schema.json) listing every candidate. This lets an operator A/B-compare tracks in the preview portal before committing one.
--duration <seconds>— desired track length (forwarded to each backend).--backends suno,lyria,lyria3,flowmusic— restrict to a comma-separated subset (unavailable ones are skipped; an unknown id errors). Default = every available backend.--lyrics "<[Verse]…>"— supply your own lyrics ([Verse]/[Chorus]-tagged) for a vocal song. FlowMusic only (instrumental-only backends ignore it).--instrumental— force an instrumental render. FlowMusic only.--dry-run— plan + write the artifact without calling any provider or needing keys (the candidate audio files are not downloaded).--select <backendId>— mark the human-chosen candidate: setssoundtrack.json.selectedAND writes that candidate's path into the project manifestsoundtrackfield, which the preview portal reads to render the headline<audio>player. (Does not regenerate.)
If only one backend is configured it still works (single candidate). When the preview portal finds soundtrack.json with >1 candidate it renders one labelled <audio> player per backend (the selected one flagged as the headline); single-soundtrack projects without soundtrack.json keep the legacy behaviour.
FlowMusic (Lyria 3 Pro vocal songs). The flowmusic backend generates full vocal songs (and instrumentals) via Google Lyria 3 Pro on useapi.net — the only music backend that sings. It reuses the same USEAPI_API_TOKEN as the dreamina-useapi / runway-useapi video routes (no new token), and requires a FlowMusic (flowmusic.app) account registered on that useapi.net subscription. It submits async, polls to completion, and downloads the first of the A/B clip pair as .mp3. Pair it with --lyrics for a scripted vocal or --instrumental for a bed. Env: USEAPI_API_TOKEN (required); optional VCLAW_FLOWMUSIC_ACCOUNT (pin the flowmusic.app account email — omitted → useapi auto-selects), VCLAW_FLOWMUSIC_GHOSTWRITER (standard|pro, lyrics-writer used when the model writes the lyrics).
Narration / TTS (vclaw video narrate)
vclaw video narrate --project <slug> --text "<script>" synthesizes a single narration clip via a TTS backend (the audio-platform registry) and writes it to projects/<slug>/artifacts/audio/narration.{wav,mp3}, alongside a typed narration.json artifact (schema: schemas/video/artifacts/narration.schema.json). Two backends are registered:
gemini-tts(default) — Gemini APIgemini-2.5-flash-preview-tts, an API-key product (not Vertex) resolving a key from the Gemini key pool (GEMINI_API_KEYS/GOOGLE_API_KEYS/GOOGLE_API_KEY). Returns raw 24kHz mono PCM wrapped as WAV; duration computed from the PCM byte count. Requires the GeminigenerativelanguageAPI enabled on the key's project (else HTTP 403).elevenlabs-tts— ElevenLabseleven_multilingual_v2(--backend elevenlabs-tts). RequiresELEVENLABS_API_KEY;--voiceis an ElevenLabs voice_id (default "Rachel"). Returns mp3; duration estimated from text length. A Gemini-free alternative.
Without --backend, narration uses an automatic fallback chain: it tries the available backends in registry order (gemini-tts, then elevenlabs-tts) and falls back to the next when one fails at runtime — so a gemini-tts 403 (API not enabled) transparently lands on elevenlabs-tts when its key is set. narration.json records the winner as backendId and any failed-over backends in fallbackFrom. An explicit --backend is strict (no fallback — the error surfaces directly).
--text "<script>"/--text-file <path>— the narration script (one is required;--textwins if both are given).--voice <name>— prebuilt voice name (defaultKore).--backend gemini-tts— pin a specific backend (defaults to the first available; an unavailable named backend errorstts_failed).--video-duration-ms <ms>— when given, the artifact also embeds aplanNarrationFit()plan (tempo/loopVideo/targetDurationMs/warnings) so the assemble step can fit narration to the video bed (atempo speed-up within threshold, otherwise loop the visual bed).--dry-run— estimate duration from text length and write a placeholder WAV without any network call or key (availability is still gated on a key being present).
Per-character dialogue (vclaw video dialogue)
vclaw video dialogue --project <slug> --turns "Alice: Hello || Bob: Hi there" synthesizes one TTS clip per dialogue turn over the same audio-platform TTS registry (gemini-tts), writing each clip to projects/<slug>/artifacts/audio/dialogue-<i>-<name>.wav and persisting a typed dialogue.json artifact (schema: schemas/video/artifacts/dialogue.schema.json).
--turns "Name: line || Name2: line2"(required) — turns separated by||; each turn is split on the first:into{ name, line }. Empty pieces are skipped.--voice <name>— applied to every turn.--backend gemini-tts— pin a specific TTS backend (defaults to the first available; an unavailable named backend errorstts_failed).--dry-run— estimate duration per turn and write placeholder WAVs without any network call (availability is still gated on a Gemini key being present).
JSON output: { slug, action: "dialogue", dryRun, clips: [{ name, path, durationMs }], artifactPath }.
Sound effects / foley (vclaw video sfx)
vclaw video sfx --project <slug> --prompt "whoosh" generates one sound-effect clip from a text prompt via an SFX backend (currently elevenlabs-sfx, the ElevenLabs Sound Generation API — requires ELEVENLABS_API_KEY), writes it to projects/<slug>/artifacts/audio/sfx-<n>.mp3, and appends it to a typed sfx.json artifact (schema: schemas/video/artifacts/sfx.schema.json).
--prompt "<text>"(required) — the sound-effect description.--duration <seconds>— requested clip length (0.5–22s for ElevenLabs).--prompt-influence <0..1>— how strictly the backend follows the prompt.--backend elevenlabs-sfx— pin a specific SFX backend (defaults to the first available; an unavailable named backend errorsmusic_gen_failed).--dry-run— write a placeholder clip without any network call (availability is still gated onELEVENLABS_API_KEYbeing present).
JSON output: { slug, action: "sfx", dryRun, backendId, path, durationMs }.
Diegetic stills (vclaw video gen-image)
vclaw video gen-image --project <slug> --prompt "<text>" --kind <kind> generates a diegetic still — an in-world prop, an on-screen screen (UI / dashboard), or an overlay graphic (e.g. a "SYSTEM COMPROMISED" alert). Three backends, selected by --backend (default gobananas — omitting the flag is byte-identical to the pre-backend behavior):
gobananas(default) — the Go Bananas image API (the samePOST /imagesbackendcharacter-auto-createuses; resolvesGO_BANANAS_API_KEY/GO_BANANAS_API_URL, no OpenAI key).openai— the OpenAI Images API (gpt-image family,OPENAI_API_KEY). Override the endpoint withVCLAW_OPENAI_IMAGE_ENDPOINT(e.g. an Azure/proxy deployment) and the model withVCLAW_OPENAI_IMAGE_MODEL.flow— Google Flow via useapi.net (POST /google-flow/images; needsUSEAPI_API_TOKEN+USEAPI_ACCOUNT_EMAIL). See the Flow backend notes below.
The result is written under projects/<slug>/assets/props/ and can be composited onto footage with the assemble overlay builders. Pairs with the storyboard contract: generate the screen, overlay it.
--kind prop|screen|overlay(required) — weaves a per-kind render directive into the prompt:screen= flat UI capture (no bezel),overlay= centered on a solid background for keying,prop= isolated on neutral. Screens and overlays keep text (they are UIs/alerts); props suppress it.--scene <i>— tag the output filename (screen-scene001.png) and the registration hint.--out <path>— override the output path (defaultassets/props/<kind>[-scene<i>].png).--aspect <ratio>— override the aspect (default16:9for screen,1:1otherwise).--model <id>— backend model id (Go Bananas defaultgemini-pro-image; forflowit must be one of the Flow models below).--dry-run— print the composed request + output path without spending (no key needed).
The non-dry output includes a registerHint — the vclaw video assets command to attach the generated still to a scene so it flows into the preview portal.
Flow backend (--backend flow)
The Flow backend renders through Google Flow's image models with reference and saved-character slots:
| Model | Reference budget | Auto-selected when |
|---|---|---|
imagen-4 | ≤3 reference images | 0 references (best pure text-to-image) |
nano-banana | ≤10 reference images | 1–3 references (character consistency) |
nano-banana-pro | ≤10 reference images | 4+ references (max references, upscale-able) |
--model pins one explicitly; otherwise it is auto-selected from the TOTAL reference-image count. Character refs count toward the same per-model budget (each contributes its saved image count — the -imgs:N- segment of the ref — default 1), so e.g. imagen-4 with 2 --ref + 2 single-image --character values fails fast with a budget error before any upload.
Flow-only flags (rejected with invalid_flag_value on other backends — never silently ignored):
--ref <path|mediaGenerationId>(repeatable, ≤10) —reference_1..Nslots in order. Values are classified by shape: anything shaped like an already-uploaded media ref (user:...prefix) is passed through verbatim; everything else is treated as a local image path, must exist (a typo'd path fails fast withinvalid_flag_valuebefore any upload — it is never silently shipped as a bogus id), and is uploaded first (POST /google-flow/assets, PNG/JPEG) with itsmediaGenerationIdsubstituted.--aspect <ratio>— one of16:9,4:3,1:1,3:4,9:16,auto(plus the legacy aliaseslandscape/portrait); anything else is rejected withinvalid_flag_value. Defaults to16:9for--kind screen,1:1otherwise.autoderives the aspect from the references and therefore requires a nano-banana model AND at least one reference image (--ref/--character) —imagen-4or a reference-less request rejects it.--character <name|ref>(repeatable, ≤7) —character_1..Nslots in order. A name resolves case-insensitively via the project'sflow-characters.json(vclaw video flow-register-characters); a value that is neither registered nor shaped like a Flow character ref (user:...-character:...) fails fast.--count <1-4>— images per generation (default 1; the API default of 4 would 4x the spend). Extra images are written next to--outwith-2/-3/-4suffixes before the extension.--seed <n>— non-negative integer for reproducible results.
Inline @-markers: the prompt may anchor a slot to a position in the text with @reference_1..10 / @character_1..7 (case-insensitive, opt-in). Every marker must have a matching slot or the API would 400, so the CLI validates markers before any upload or spend — including under --dry-run. (@referenceImage_N / @referenceAudio_N are video-endpoint markers and are rejected in image prompts.)
--dry-run prints the fully-composed POST /google-flow/images params plus plannedUploads (local --ref paths are listed and shown verbatim in reference_N; a real run uploads them first). Example:
vclaw video gen-image --project cyber --kind screen \
--backend flow --model nano-banana \
--prompt "breach dashboard beside @character_1" \
--ref ./assets/props/logo.png --character Bunty --count 2 --dry-runThe non-dry result includes paths (every written file), the generated mediaGenerationIds (reusable as --ref inputs downstream), and uploadedReferenceIds for any local refs that were uploaded.
Motion-graphics overlays (vclaw video overlay)
vclaw video overlay --input <video> --output <path> composites a motion-graphics overlay onto a video via FFmpeg. Exactly one mode is required:
--graphic <png>— overlay a PNG/alpha image, time-gated (--start/--end), alpha-faded (--fade-in/--fade-out), positioned (--position, 8 presets +full), and--opacity. This is the font-free path and pairs withgen-image: generate a "SYSTEM COMPROMISED" / dashboard screen, then overlay it (real-render validated).--alert "<text>"— burn a pulsing alert (--pulse-hz,--color,--font-size).--lower-third "<text>"— burn a boxed name/role caption.
The two text modes use the FFmpeg drawtext filter and require an ffmpeg built with libfreetype; on a drawtext-less build, render the text to a PNG (e.g. via gen-image) and use --graphic instead. --dry-run prints the planned ffmpeg command without running it. The command is file-scoped (no --project).
Flag value constraints (rejected with invalid_flag_value): --start/--end/ --fade-in/--fade-out are non-negative seconds, --opacity is a 0..1 alpha, and --pulse-hz/--font-size must be strictly positive. Empty numeric values are rejected (they would otherwise coerce to 0), and --color accepts only a colour name or #hex (optionally @opacity) so nothing can inject into the ffmpeg filter.
Motion-overlay reels (vclaw video motion-overlay)
vclaw video motion-overlay --input <video-path> (--project <slug> | --output-dir <path>)
[--layout split|overlay|motion-only|avatar-host] # default: split
[--style apple-clean|editorial-dark|knowledge-tool] # default: apple-clean
[--accent <hex>] [--delivery local|flow-web|flow-api]
[--render v2v|local] [--kicker <text>] [--headlines] [--icons]
[--emit-flow-pack] [--restitch <flow-outputs-dir>]
[--lang <code>] [--max-take-seconds 10]
[--transcript <path>] [--gb-character <Name:ID>]
[--gb-character-image <path>] [--gb-voice <preset>] # avatar-host
[--host-engine omni-r2v|veo-i2v] # avatar-host, default omni-r2v
[--host-retries <n>] # avatar-host, default 3
[--host-look <text>] [--no-host-chain] # avatar-host consistency
[--preview] [--root <path>] [--execute --confirm-spend]Turns an existing talking-head video into a reel with motion-graphics overlays synced to the speech, driven by Google Flow's Omni Flash V2V (kinetic typography / icons / metaphors painted on the footage, original voice preserved).
Plan/dry by default — no provider spend. The pipeline is: ingest (ffmpeg probe + audio extract + frame-accurate take cuts + reference frames) → Gemini STT (or a bring-your-own --transcript <path> JSON) → sentence-boundary slice into ≤ --max-take-seconds (default 10s) takes → per-take overlay-prompt composition → writes a work folder (source/ takes/ frames/ prompts/), a README, and the motion-overlay-plan.json manifest (schemaVersion 1). --preview also renders the preview-portal review/review.html approval surface (aspect-aware cards).
--render local (recommended) is the free, reliable render path. Because the omni-flash V2V "add-overlay" edit is moderation-blocked for most input clips (FINISH_REASON_INPUT_VIDEO_EDIT, input-specific), --render local renders the finished reel natively — each segment becomes a broadcast lower-third (SVG → sharp PNG → ffmpeg overlay, no freetype) over the source, original audio kept. It costs nothing (no --confirm-spend gate), writes motion-overlay-local.mp4, and --kicker <text> sets the small brand label. --style picks the card look (apple-clean rounded frosted · editorial-dark squared UPPERCASE poster · knowledge-tool serif + lavender), and --headlines adds frame-filling anchor-word headlines with the accent * beat-marker synced to the spoken moment.
--render v2v (default) --execute renders via omni-flash V2V and is gated behind --confirm-spend (exit-3 spend_confirmation_required otherwise, so no provider is ever silently called). Per take it runs omni-flash V2V → restores the original take audio via ffmpeg -map 0:v -map 1:a -c:v copy -c:a aac → clip-stitches the audio-restored takes (in order) into motion-overlay-reel.mp4.
Layouts: split (graphics top, speaker bottom), overlay (graphics over the speaker with safe areas), motion-only (speaker removed, full-frame graphics narrated by their voice), and avatar-host (Layout D). The avatar-host layout replaces the speaker with an identity-locked character that speaks each line in Omni's own voice and requires --gb-character <Name:ID> (parsed on the final :, so Dr. Vox:97 works) plus, at --execute, --gb-character-image <path> (the R2V reference still) and optional --gb-voice <preset> (default Puck). Under --execute --confirm-spend it generates a per-take host clip with omni-flash R2V + native voice (Omni produces the speech + lip-synced video together — genuinely lip-synced, NOT moderation-blocked), stitches the clips into avatar-reel.mp4, then re-transcribes the avatar's own speech and renders local lower-thirds into motion-overlay-avatar.mp4 (the caption pass is best-effort).
The Flow safety filter rejects a benign R2V generation probabilistically, so across a multi-take reel a single rejected take would otherwise fail-fast the whole run. Two safeguards make it robust: each take is retried up to --host-retries (default 3) — a plain retry of the same line usually clears — and generation is resumable: a host clip that already exists on disk (host/take-NN.mp4 from a prior run, written atomically) is reused, never regenerated, so re-running after a mid-reel failure does not re-spend on the takes that already succeeded.
Character consistency — two engines (--host-engine). R2V treats the reference as a loose influence, so the talking avatar drifts (face/wardrobe/backdrop) across independently-generated takes — and no scriptable path locks identity and gives native voice at once (Flow @Character is web-UI only). So avatar-host offers a fork:
omni-r2v(default) — native voice + lip-sync, loose identity mitigated by--host-look <text>(pins a stable appearance + fixed setting on every take's prompt, killing backdrop/wardrobe jumps) and cross-take chaining (on by default,--no-host-chainto disable; seeds each take from the previous take's last frame).veo-i2v— every take starts from the same character still as the literal first frame (Veo 3.1 I2V), so frame 0 of every take is pixel-identical → tight identity, but silent (captioned from the planned script; add a VO/soundtrack separately). Landscape-only. Shares the retry + resume plumbing — a slow provider queue can time a take out; re-run to resume from it (completed takes are reused).
Every side effect (Gemini STT, ffmpeg, omni-flash V2V, and the omni-flash R2V host generation) is behind an injectable interface, so the command is fully unit- and e2e-tested offline with no network and no spend. Full guide: docs/MOTION_OVERLAY.md.
The JSON returned by vclaw video status now also includes referenced characterBindings so project-facing status surfaces can show the same identity anchors without reparsing storyboard.md.
vclaw video readiness now also includes a warnings array. Current warnings include image-input aspect/size problems and non-blocking identity-sheet quality signals such as reference-sheet-thin-identity-coverage.
vclaw video status now also includes:
characterProfilescharacterHydrationSummary
so a later inspection can still show how the cast was assembled after the initial video create response is gone.
When a review file has been generated, status and the project index also carry the storyboardReviewPath so review tooling can link directly to the current artifact.
The same storyboardReviewPath now flows through:
vclaw video reportvclaw video export-csvvclaw video export-obsidianvclaw video sync-obsidiandashboard viewsvclaw video next-actionswhen approval is waiting on storyboard review
The Next Actions.md note generated by sync-obsidian now includes the same review link when a project is waiting on storyboard approval.
When present, next-actions also carries storyboardReviewGeneratedAt, and the generated note includes that freshness inline with the review link.
vclaw video doctor-project now also flags projects whose storyboard checkpoint is awaiting-approval but whose storyboard.md review artifact is missing.
vclaw video doctor-portfolio now also reports a portfolio-level missingStoryboardReviewProjects count for the same workflow invariant.
It now also reports staleStoryboardReviewProjects when approval is pending but the storyboard changed after the last generated review.
vclaw video storyboard-review now also appends a storyboard.review.generated event, so the review workflow shows up in timeline-style exports and history.
When stale review blocks execution, the runtime now emits a storyboard.review.stale.blocked event so timeline/history surfaces capture the enforcement step as well.
When review events exist, status and index now also expose storyboardReviewGeneratedAt alongside storyboardReviewPath.
The same surfaces now also expose storyboardReviewExists, so tooling can tell whether a review has ever been generated before trying to reason about freshness.
They now also expose a normalized storyboardReviewState field with one of:
missingcurrentstale
The same storyboardReviewState now flows through:
vclaw video reportvclaw video export-csvvclaw video export-obsidianvclaw video sync-obsidiandashboard viewsvclaw video next-actions
vclaw video report-diff now also exposes:
reviewStateChangedwhen the review-state ladder changes between snapshotsplatformChangedwhen the stored project platform changes between snapshotsexecutionProfileChangedwhen the normalized execution profile changes between snapshotslegacyImportChangedwhen captured legacy import diagnostics change between snapshots
Its top-line summary now also carries deltas for:
legacyImportedProjectsDeltalegacyQueueDriftProjectsDeltalegacyNestedOutputProjectsDelta
The same storyboardReviewExists now flows through:
vclaw video reportvclaw video export-csvvclaw video export-obsidianvclaw video sync-obsidiandashboard views
The same storyboardReviewGeneratedAt now flows through:
vclaw video reportvclaw video export-csvvclaw video export-obsidianvclaw video sync-obsidiandashboard views
When the storyboard changes after the latest review generation, status now marks the review stale and next-actions prioritizes refreshing the review artifact before approval.
The same stale-review signal now flows through:
vclaw video reportvclaw video export-csvvclaw video export-obsidianvclaw video sync-obsidiandashboard views
That same stale-review signal now gates director runtime operations as well:
vclaw video executevclaw video execute-status
The same referenced characterBindings now flow through:
vclaw video reportvclaw video export-csvvclaw video export-obsidianvclaw video indexvclaw video sync-obsidian
The same cast provenance now also flows through:
vclaw video statusvclaw video indexvclaw video reportvclaw video export-csv
The same review file now includes a focused director preflight result. Current preflight coverage includes:
- provider-risk content hazard detection
- stored Go Bananas id resolution and reference-image presence checks
- remote reference-asset probe failures
- pronoun drift warnings against known character descriptions
- repeated adjacent-scene warnings
- prompt-quality warnings/errors from
docs/PROMPT_QUALITY.md - dialogue duration fit warnings/errors (
DIALOGUE_DURATION_OVERFLOW) - reference-sheet validation and Go Bananas reference checks
Supported env controls for this flow:
DIRECTOR_AUTO_FIX_CONTENT=1auto-rewrites known provider-risk phrases before preflight re-checks the storyboardSKIP_DIRECTOR_PREFLIGHT=1bypasses the preflight step and goes straight to the storyboard approval gateDIRECTOR_STRICT_PROMPT_QUALITY=1promotes prompt-quality warnings to blocking errorsDIRECTOR_STRICT_DIALOGUE_FIT=1promotes dialogue duration warnings to blocking errors
Direct CLI surface:
vclaw video director-preflight --project <slug> [--root <path>] [--apply-content-fixes]
vclaw video preflight --project <slug> [--root <path>] [--apply-content-fixes]
vclaw video storyboard-review --project <slug> [--root <path>] [--mode storyboard|director] [--apply-content-fixes]For director mode, storyboard-review now writes storyboard.md and, when preflight passes, marks the storyboard checkpoint awaiting-approval without starting execution.
When --apply-content-fixes is set, director-preflight/preflight and storyboard-review regenerate artifacts/story-bible.json after the fixes land so the continuity bible reflects the corrected storyboard (see Story bible).
Projects in awaiting-approval now surface as needs-review across the index, dashboard, and metrics layer instead of generic active.
Portfolio metrics now also expose staleStoryboardReviewProjects so stale approval reviews are visible in the summary layer.
They also expose unreviewedStoryboardProjects, which counts projects that have not generated a storyboard review yet.
They now also expose byReviewState with explicit missing, current, and stale counts.
Local media post-production (file-level utilities)
Free, local ffmpeg utilities over a project's final output (--project <slug>, resolved via final/ or the publish report) or any file (--file <path>). All emit machine-readable JSON.
| Command | Usage | What it does |
|---|---|---|
verify-final | vclaw video verify-final (--project <slug> | --file <path>) [--output-dir <path>] | Probe + sanity-check the final master (dims/duration/streams). |
make-vertical | vclaw video make-vertical (--project <slug> | --file <path>) [--output <path>] | 9:16 vertical cut (1080×1920 scale-to-cover + center crop). |
make-square | vclaw video make-square (--project <slug> | --file <path>) [--output <path>] | 1:1 square cut (1080×1080 scale-to-cover + center crop). |
make-loop | vclaw video make-loop (--project <slug> | --file <path>) [--output <path>] | Boomerang loop (forward + reversed concat). |
thumbnail | vclaw video thumbnail (--project <slug> | --file <path>) [--output <path>] [--text <title>] | Poster-frame thumbnail, optional title text. |
burn-subtitles | vclaw video burn-subtitles (--project <slug> | --file <path>) --subtitle <path> [--output <path>] | Burn a subtitle file into the video. |
remix-narrated | vclaw video remix-narrated --project <slug> [--output <path>] | Re-stitch the project's narrated scene clips into one master. |
Archive, playbooks, and library lookups
| Command | Usage | What it does |
|---|---|---|
archive-project | vclaw video archive-project --project <slug> [--archive-dir <path>] [--cleanup] | Move a finished project out of the active workspace (optionally pruning state). |
playbook-list | vclaw video playbook-list | List the bundled operator playbooks. |
playbook-show | vclaw video playbook-show --name <playbook-name> | Print one playbook. |
list-library | vclaw video list-library [--name-regex <pattern>] | List Go Bananas library characters (see also find-library / library find). |
Live execution adapters
vclaw video produce submits a JSON payload to a route-specific adapter command via stdin. Configure one of:
VCLAW_VEO_USEAPI_ADAPTER
VCLAW_SEEDANCE_DIRECT_ADAPTER
VCLAW_RUNWAY_USEAPI_ADAPTER
VCLAW_DREAMINA_USEAPI_ADAPTERThe adapter should print JSON to stdout. If produce returns externalJobId, vclaw records that in the execution report and leaves the assets stage pending. execute-status then sends a poll request to the same adapter and, on completion, merges generated outputs into the canonical asset manifest and advances the project to review.
In candidate mode (per-scene submits, e.g. --auto-chain) each scene carries its own adapter job id on its candidate. If the most recent execute left a blocked, job-less execution report (a later scene failed to submit), execute-status still polls every pending candidate that has its own job id and promotes each independently — so one blocked scene never strands the rest of the chain's in-flight jobs. With no candidate artifact (legacy single-job runs) the blocked report is reported as-is, unchanged.
For built-in core-route adapters:
VCLAW_SEEDANCE_DIRECT_SUBMIT_CMD
VCLAW_SEEDANCE_DIRECT_POLL_CMD
VCLAW_VEO_USEAPI_SUBMIT_CMD
VCLAW_VEO_USEAPI_POLL_CMDIf VCLAW_SEEDANCE_DIRECT_ADAPTER or VCLAW_VEO_USEAPI_ADAPTER is unset, vclaw automatically falls back to the built-in adapter binary for that route.
Every produce and execute-status path appends generation.telemetry.recorded events to projects/<slug>/events/events.jsonl. These records capture route, operation, task count, prompt/reference summary, external job id, provider cost fields, timing fields, issues, and output-ingest count when available.
For seedance-direct, if VCLAW_SEEDANCE_DIRECT_SUBMIT_CMD / VCLAW_SEEDANCE_DIRECT_POLL_CMD are also unset, the built-in adapter can talk directly to the Seedance API using:
SUTUI_API_KEY
VCLAW_SEEDANCE_BASE_URL # optional, defaults to https://api.xskill.aiFor veo-useapi, if VCLAW_VEO_USEAPI_SUBMIT_CMD / VCLAW_VEO_USEAPI_POLL_CMD are unset, the built-in adapter can run the local vclaw-cli workspace using:
VCLAW_VEO_CLI_ROOT # optional, defaults to <workspace>/vclaw-cli
VCLAW_VEO_BUN_BIN # optional, defaults to bun
VCLAW_VEO_OUTPUT_DIR # optional, defaults to <vclaw-cli>/output-videosOmni-flash passthrough (veo-useapi)
The native transport forwards the following execution-profile / per-scene fields to flow.ts when present (absent → byte-identical legacy command):
executionProfile.veoModel(fast|quality|lite|free|omni-flash) →flow.ts -m(resolved to the useapi model string bymapModelToUseApi).omni-flashunlocks native audio and video-to-video;lite→veo-3.1-lite(cheaper Veo tier) andfree→veo-3.1-lite-low-priority(the relaxed / explore lane — Ultra-tier-gated at the provider, errors clearly otherwise); defaults toqualitywhen unset.- Per-scene
voicePreset(one of the 30 Flow v1 voice presets) →--voice(FlowreferenceAudio_1). omni-flash-only — a voice preset on any otherveoModelfails the route-capability check (downgraded to a warning underVCLAW_ALLOW_UNSAFE_MODELS=1). - Per-scene
durationSeconds→--duration, emitted only for the allowlisted values4 | 6 | 8 | 10(mirrors theflow.tsallowlist); other values are dropped rather than forwarded. - Per-scene
referenceVideoMediaId→--ref-video(FlowreferenceVideo_1, video-to-video edit). omni-flash-only (same guard as voice). This is the dedicated V2V edit source — not the scene-chaining seed, which any model supports. - Image references are model-aware (encoded in the prompt, which is how
flow.tsreads them). On Veo models an image reference is the first-frameimage:<path>startImage (I2V). On omni-flash (which rejectsstartImageby default) the same references becomeingredients:<p1,p2,…>(referenceImage_*, R2V, up to 7). Mutually exclusive with V2V — whenreferenceVideoMediaIdis set, the R2Vingredients:prefix is suppressed. - omni-flash First-Frame (gated, build-ahead).
--scene-first-frame <sceneIndex>[,<sceneIndex>…]onstoryboardmarks scenes to deliver their single reference as a literal first frame (image:startImage / I2V) on omni-flash — locking the opening frame while keeping native voice — instead of the loose R2Vingredients:path. This is gated by theVCLAW_OMNI_FIRST_FRAMEenv flag and OFF by default: with the gate off the scene flag is ignored (a stderr advisory is logged) and behavior is byte-identical. The feature is build-ahead / UNVERIFIED-LIVE — useapi.net marks omni-flash frames mode "coming soon", so the in-process andvclaw-clivalidators only relax their omni-flashstartImageblocks when the gate is set. Inferred wire shape to confirm when useapi ships it:{ model:"omni-flash", startImage:<mediaId>, referenceAudio_1:<voice>, duration }. - Voice needs a reference.
referenceAudiois rejected by the provider on pure text-to-video, so voice on omni-flash requires either an image reference (R2V) orreferenceVideoMediaId(V2V); the route-capability check now fails fast otherwise. R2V + voice is the reliable narrated path (V2V + voice is heavily moderation-gated).
Authoring the fields:
--veo-model fast|quality|lite|free|omni-flashonset-execution-profile/brief/create/clone-*persistsveoModelinto the brief execution profile.--scene-voice <sceneIndex>:<preset>and--scene-ref-video <sceneIndex>:<mediaId>onstoryboardset the per-scenevoicePreset/referenceVideoMediaId(repeatable, same shape as--scene-character/--scene-color).--scene-first-frame <sceneIndex>[,<sceneIndex>…]onstoryboardsets the per-scenefirstFrameflag (repeatable; each value is one index or a comma-separated list). Honored only whenVCLAW_OMNI_FIRST_FRAMEis set at execution time (gated build-ahead, see above).
For dreamina-useapi (Dreamina / CapCut-ByteDance Seed, Seedance 2.0 via useapi.net — keyframe image-to-video plus text-to-video, 1080p on CA accounts), the built-in native transport (src/video/native-dreamina.ts) talks directly to the useapi.net Dreamina API. It reuses the same USEAPI_API_TOKEN as runway-useapi (no new token) and reads the account/region from env:
USEAPI_API_TOKEN # required, shared with runway-useapi
VCLAW_DREAMINA_ACCOUNT # required, e.g. "CA:ai@example.com" (already configured server-side)
VCLAW_DREAMINA_REGION # optional, defaults to CA
VCLAW_DREAMINA_MODEL # optional, defaults to seedance-2.0
VCLAW_DREAMINA_OMNI_RATIO # optional, "1" to force the project aspect ratio in Omni Reference modeBy default Omni Reference mode (multi-image / any video or audio reference) auto-detects the output aspect ratio from the references — but Dreamina defaults that to landscape (16:9) even when the references are portrait, so a 9:16 project comes out 16:9. Set VCLAW_DREAMINA_OMNI_RATIO=1 to pin the project's aspect ratio through Omni mode (the API accepts an explicit ratio alongside the omni_N_*Ref fields — live-confirmed). Default off → ratio is auto-detected as before (byte-identical). Only affects Omni mode; first_frame and text-to-video are unchanged.
The account must already be registered with useapi.net (POST /accounts with {email, password, region, maxJobs} is done out-of-band); the transport only needs the account id + token at submit time. Image-to-video uploads the first image reference via POST /dreamina/assets/<account> to obtain an assetRef, then passes it as firstFrameRef on POST /dreamina/videos; poll uses GET /dreamina/videos/<jobid> and downloads response.videoUrl. As with runway-useapi, you can override the whole route with VCLAW_DREAMINA_USEAPI_ADAPTER or the per-action shims VCLAW_DREAMINA_USEAPI_SUBMIT_CMD / _POLL_CMD / _CANCEL_CMD.
Seedance 2.0 rejects real human faces at content moderation — use illustrated or stylized characters, or a Runway-generated real-face start frame.
Execution profile normalization
plan now emits a normalized execution profile and the runtime uses it.
Supported fields:
aspectRatioqualityresolutiongenerateAudiooutputCount
You can override them through brief metadata:
{
"executionProfile": {
"aspectRatio": "9:16",
"quality": "quality",
"resolution": "1080p",
"generateAudio": false,
"outputCount": 2
}
}The same profile can now be set directly from the CLI through:
briefclone-initclone-executeset-execution-profile
Cost estimates
vclaw video cost-estimate [--project <slug>] [--root <path>] [--scenes <count>] [--clip-duration <seconds>] [--new-characters <count>] [--narration on|off]Direct flag estimates use the static model. Project estimates infer scene count, average duration, narration, and new-character count from project artifacts when possible. If completed seedance-direct telemetry with provider-reported USD is available under the same root, the estimate reports historical-telemetry in estimateSource and includes a telemetry summary. Otherwise it reports static-default.
Compatibility aliases
execution-planremains an alias forplanexecuteremains an alias forproduce- deprecation notices are written to
stderrso JSONstdoutstays machine-readable
Multi-shot prompt
vclaw video multi-shot (--presets | --plan | --validate | --fix | --auto) [flags]Scaffolds, validates, and (via Gemini) authors compressed timecoded multi-shot cinematic prompts — structured shot sequences targeting a fixed duration (default 15 s) with enforced non-repeating camera parameters and a Location/Style/Audio metadata block.
Music videos (vclaw video music-video)
vclaw video music-video --config <music-video-config.json>
[--work-dir <path>] # default: the config's directory
[--output <path>] # default: <work-dir>/master.mp4
[--execute] [--dry-run] # plan/dry by default; --execute renders
[--ffmpeg-bin <path>] [--ffprobe-bin <path>]The vocal-synced, beat-exact music-video assembler — it turns an operator-authored config into a finished cut whose performers land on their own vocals and whose baked lip-sync stays locked to the muxed song, with zero cumulative drift. Fully local: ffmpeg only, no provider and no spend, so there is no --confirm-spend gate.
The config (schemas/video/artifacts/music-video-config.schema.json, hand-authored) names the song + its length, a clip registry (`id → path
- probed duration
), the **B-roll pools** (action/atmo/trio/vanish), and either an **explicit vocal map** (sections carrying theirperformerClip) or a **transcript** (whisper-style) the assembler auto-classifies into rap / hook / instrumental / outro by **word density** — plusperformers: { rap, hook }to pin the rapper to the rap and the singer to the hook. An optionalgradeid applies one colour pass over the whole cut, andbeats` (seconds) snap cuts to the beat grid.
The pipeline: buildVocalMap (transcript → vocal map) → planVocalSync (performer-on-vocal, time-aligned so lips stay locked across B-roll cutaways, de-patterned B-roll via shuffle-bag + stepped in-points) → frame-exact per-segment cut (-frames:v round(dur·fps), never -t, with -nostdin) → concat (-c copy) → one grade pass + mux the song. Plan/dry by default prints the resolved vocal map, the per-cut summary (performer vs B-roll counts), and the ffmpeg step list without spawning. --execute renders, then asserts the built master's duration equals the planned duration within one frame (audio_sync_drift otherwise) so sync can never silently regress.
Character-ad stitch (vclaw video stitch-ad)
Assemble ordered scene clips into a short ad with cross-dissolves and an optional instrumental music bed laid UNDER the native voice (plus a one-shot SFX). The native character-ad finishing recipe — pair it after flow-r2v scenes and before title-card / make-vertical.
vclaw video stitch-ad --clip <path> [--clip <path> ...] --out <path>
[--dissolve <sec>] # cross-dissolve length (default 0.6)
[--width <px>] [--height <px>] [--fps <n>] # normalize target (default 1280x720 @24)
[--bed <track>] [--bed-level <0-1>] # music bed UNDER the voice (default level 0.13)
[--sfx <track>] [--sfx-at <sec>] [--sfx-level <0-1>] # one-shot SFX (default level 0.4)
[--dry-run] # print the planned ffmpeg command onlyxfade cross-dissolves the video and acrossfade crossfades the clips' native audio (the R2V voice). The bed is looped/trimmed to the cut, faded in/out, and mixed low under the voice — never overwriting it. Clips are normalized to a common WxH/fps. Fully local FFmpeg, no spend.
# stitch four flow-r2v scenes with a noir bed, then title-card + vertical
vclaw video stitch-ad --clip s1.mp4 --clip s2.mp4 --clip s3.mp4 --clip s4.mp4 \
--bed bed.mp3 --sfx match.mp3 --sfx-at 7.6 --out ad-cut.mp4Music-video titles (vclaw video title-card)
vclaw video title-card --input <video> --output <path>
(--lower-third "<title || subtitle>" | --end-card "<title || subtitle>" | both)
[--lt-start <s>] [--lt-end <s>] # lower-third window (default 4..11, clamped to length)
[--end-hold <s>] # end-card seconds before EOF (default 4.5)
[--title-font <alias|path>] [--body-font <alias|path>] # didot/avenir/devanagari/...
[--title-color <#hex>] [--sub-color <#hex>] [--accent-color <#hex>] [--no-accent]
[--python <bin>] [--dry-run]Burns the titles you see in music videos — a faded lower-third early in the cut and/or a centred end card that holds to the very end — onto a finished video. The text is rasterized to a transparent full-frame PNG by Pillow + RAQM (HarfBuzz shaping), so it works on any ffmpeg build (no libfreetype needed) and any script, including Devanagari/Arabic — the vowel marks shape and stack correctly (measure-ink-bottom-and-stack, so a tall glyph can't overlap the line beneath). Each PNG is composited as a looped input (-loop 1) so a delayed alpha fade actually animates (a static -i PNG is one frame at t=0 and a later fade=in:st=N never triggers — a real bug this avoids).
Lines are split on ||; the first line is title-weight, the rest body-weight. Type scales with the frame height so 720p and 1080p read the same. The end card fades in and holds with no fade-out to EOF; the lower third fades both ways and is clamped to the song length. Fully local, no spend. --dry-run prints the planned cards (sizes/timings) without rendering; omit it to render. Needs python3 with Pillow[raqm] on a real run (clear error otherwise).
HD finish / upscale (vclaw video finish)
vclaw video finish --input <video> --output <path>
[--backend topaz-proteus|topaz-gaia|topaz-starlight|topaz-local] # default: topaz-proteus
[--scale 1..4] [--grain 0..1] [--noise 0..1] [--recover-detail 0..1] [--sharpen]
[--topaz-cli <path>] # topaz-local
[--dry-run] [--confirm-spend]Upscales/finishes a rendered cut to a clean HD master. Hosted Topaz (Proteus default, Gaia, Starlight) runs through the apiz/xskill aggregator — it uploads the input to a temporary public host, submits the fal-ai/topaz/upscale/video task, polls to completion, and downloads the result. topaz-local instead shells a local Topaz CLI (--topaz-cli <path> or VCLAW_TOPAZ_CLI).
The anti-plastic "detail-not-sharp" recipe is on by default: denoise + halo off (noise=0, halo=0), film grain kept (clamped to the real 0.1 cap — the published schema's 0..1 is wrong for this endpoint), detail recovery high. This avoids the waxy skin a naive sharpen/denoise produces. --sharpen opts back into the sharpen path; --scale / --grain / --noise / --recover-detail override individual knobs.
Hosted backends are PAID → the command refuses without --confirm-spend (exit-3 spend_confirmation_required); --dry-run prints the resolved Topaz params for free. topaz-local is free (no gate). Hosted backends need APIZ_API_KEY (or XSKILL_API_KEY) — an sk-... key from the apiz.ai console. (realesrgan-x4plus is a planned backend with no executor yet — use a Topaz backend.)
Audio-driven lip-sync (vclaw video lipsync)
vclaw video lipsync --image <path> --audio <path> --output <path>
[--resolution 720p|1080p] # default 1080p
[--prompt "<text>"] [--turbo] [--no-normalize] [--fps <n>]
[--dry-run] [--confirm-spend]Turns a still / character keyframe + a vocal track into a lip-synced, expressive talking-head clip via OmniHuman v1.5 (fal-ai/bytedance/omnihuman/v1.5 through the apiz/xskill aggregator). It uploads the image + audio, submits the task, polls to completion, downloads the result, then normalizes it to CFR --fps (default 24) + even dimensions — load-bearing, because OmniHuman returns 25 fps and sometimes odd dimensions, which break frame-accurate -ss/-frames:v seeking in the assembler. --no-normalize keeps the raw clip.
This drives an external vocal (a rapper's verse, a singer's hook, a narrator) — it is the building block the music-video lane uses to put a performer's real vocal on their face. (Contrast motion-overlay --layout avatar-host, which makes the character speak in its own generated voice.)
Audio length is checked against the model cap up front — 1080p ≤ 30 s, 720p ≤ 60 s — with an actionable error (switch to 720p or split the vocal). PAID → refuses without --confirm-spend (exit-3 spend_confirmation_required); --dry-run plans for free. Needs APIZ_API_KEY (or XSKILL_API_KEY).
Modes
| Flag | Purpose |
|---|---|
--presets | List the registered preset contracts as JSON for agents and UIs. |
--plan | Scaffold a shot grid (timecodes + suggested camera parameters) without prose. |
--validate | Check an existing prompt text against the preset rules. Reads from --file <path> or stdin. Exits 0 if valid, 1 if errors are found. |
--fix | Apply conservative deterministic fixes and return a before/after validation report. Reads from --file <path> or stdin. |
--auto | Author the full prompt via Gemini (requires --image <path> and a configured Gemini key pool, or VCLAW_MULTISHOT_AUTO_STUB for offline/testing). |
Flags
| Flag | Default | Description |
|---|---|---|
--preset <name> | cinematic-15s | One of cinematic-15s (default, 15 s / 3–7 shots / 1500 chars), seedance-10s (10 s / 2–5 shots / 1500 chars), veo-8s (8 s / 2–4 shots / 1500 chars), runway-10s (10 s / 2–5 shots / 1000 chars). Each preset declares its own clip duration, shot-count window, per-shot duration bounds, and char budget; the Nolan styleLine and diegetic audioLine are shared. Override with --style-line / --audio-line. Unknown names fail fast. |
--provider <name> / --route <name> | — | Provider hint used when --preset is omitted. seedance* resolves to seedance-10s, veo / flow resolves to veo-8s, and runway* resolves to runway-10s. |
--from-storyboard | false | Hydrate --plan or --auto from a project storyboard scene. Requires --project <slug> and --scene <sceneIndex>. |
--shots <n> | auto (preset window) | Exact shot count for --plan. Must fall within the resolved preset's [minShots, maxShots]; out-of-range values fail fast. |
--seed <n> | random | PRNG seed for reproducible plans. |
--format <name> | default | With --plan: select the rendered output. default emits the original { preset, shots[] } JSON (unchanged). seedance-paragraph renders one flowing labeled paragraph via composeSeedanceParagraph. per-shot renders one SHOT N — NAME block per shot via composePerShotFormat. |
--lang <code> | en | With --plan and a non-default --format: wrap the rendered text for bilingual delivery. en = one fenced block; zh = one fenced block; en+zh = two labeled (EN / 中文) fenced blocks. Translation is offline/identity here — the flag surfaces the wrapper structure only; no network translation is performed. |
--category <id> | cinematic | With --plan and a non-default --format: the category descriptor (subject type, beat template, genre) that drives the composed prose. One of the 15 registered category ids (cinematic, 3d-cgi, cartoon, comic-to-video, fight-scenes, motion-design-ad, ecommerce-ad, anime-action, product-360, music-video, social-hook, brand-story, fashion-lookbook, food-beverage, real-estate); unknown ids fail fast. The category's genre drives the Style & Mood line (e.g. 3d-cgi → photoreal CGI, not the Nolan default; cinematic and the other live-action categories stay on the Nolan line). Categories with a signature hook (the six creative ids above) auto-open with it unless an explicit --hook is passed. |
--hook <patternId> | — | With --plan and a non-default --format: prepend a named opening-hook directive (Opening hook — <description>) drawn from HOOK_PATTERNS. The 12 generic ids (black-to-light, silence-to-sound, reverse-motion, beat-drop, match-cut-in, whip-reveal, speed-ramp, first-person-rush, impact-freeze, title-burn-in, slow-reveal, snap-zoom) plus the per-category libraries (e.g. scale-reveal, smash-zoom, weapon-clash-spark, speed-line-burst, hi-hat-flash-cuts, impossible-scale); unknown ids fail fast. An explicit --hook overrides the category's auto-open hook. |
--dialogue "<speaker>: <line>" | — | With --plan and a non-default --format: append spoken dialogue to the opening of the rendered text via withDialogue. Add a second speaker after a || separator ("A: hi || B: bye") to emit one replies: line. A trailing [emotion] on a line (e.g. "Mara: It is fine. [scared]") sets that speaker's emotion. A value with no colon fails fast. Omitting it leaves the rendered text unchanged. |
--emotion-cues | off | With --plan, a non-default --format, and --dialogue: rewrite each speaker's named emotion into a physical-cue descriptor (scared → eyes wide, jaw slack, breath shallow…) — models perform physical cues better than emotion names. Advisory/additive: unmapped and deliberately-excluded extreme emotions (panic, rage, …) pass through named; omitting the flag is byte-identical. |
--total-seconds <n> | 15 | Total clip duration in seconds. |
--max-chars <n> | 1500 | Character budget enforced by --validate. |
--style-line <text> | cinematic-15s default | Override the Style: metadata line. |
--audio-line <text> | cinematic-15s default | Override the Audio: metadata line. |
--image <path> | — | Reference image path; required for --auto. |
--location <text> | — | Scene location written into Location: block. |
--time <text> | natural daylight | Time of day written into Location: block. |
--character <text> | — | Character description hint passed to Gemini. |
--action <text> | — | Action description hint passed to Gemini. |
--dry-run | false | With --auto: print the resolved request and validation contract without reading the image or calling Gemini. |
--explain-issues | false | With --validate: add stable repair guidance for each unique issue code. |
--retry-invalid <n> | 0 | With --auto: retry validation failures up to n extra times, feeding the previous issue codes/messages back into the authoring request. |
--project <slug> | — | Persist the result as a multi-shot-prompt artifact under the named project. |
--root <path> | cwd | Workspace root (used with --project). |
--raw | false | With --auto: print only the prompt body, no JSON envelope. |
Output
--presets emits JSON: { presets[] } with every registered preset and its duration, shot-count, per-shot-duration, character-budget, style, and audio contract.
--plan emits JSON: { preset, shots[] }. The preset object carries name, totalSeconds, minShotSeconds, maxShotSeconds, minShots, maxShots, maxChars, styleLine, and audioLine. Each shot has index, start, end, timecode, shotSize, lens, angle, movement. With --from-storyboard, output also includes source and resolved input so agents can see exactly which scene, characters, action, location, and time of day were used.
With --format seedance-paragraph or --format per-shot, --plan instead emits the rendered prompt text (not JSON), wrapped in fenced code block(s) per --lang (en default = one block, en+zh = two labeled blocks). --hook prepends a named opening-hook directive and --dialogue appends spoken dialogue to the opening line (both apply only on non-default formats and are post-render text transforms — the composers stay pure). --format default (or omitting any of these flags) keeps the original JSON output unchanged.
--validate emits JSON: { valid, charCount, issues[] } where each issue has code, severity, message. With --explain-issues, it also emits explanations[] containing code, summary, and suggestedFix. Exit code 1 when any issue has severity: "error".
--fix emits JSON: { original, fixed, appliedFixes[] }. The first version is deliberately conservative: it normalizes whitespace and can add missing metadata from the resolved preset plus --location / --time. It does not creatively rewrite shot prose or timecodes.
--auto emits JSON: { preset, location, timeOfDay, shots, promptText, charCount, valid, issues, attempts, generatedAt }. The shots[] array is parsed from the authored prompt so project artifacts are usable by downstream review and execution code. attempts[] records every validation attempt when --retry-invalid is used. With --from-storyboard, output and persisted artifacts also include source. With --raw, prints only promptText. With --dry-run, it emits { mode, dryRun, preset, source?, input, validationContract } and makes no model call.
Note: When
--projectis supplied, the artifact is persisted to disk even when validation fails (valid: false); the issues array is recorded and the process exits with code1. A persisted artifact does not imply the prompt passed validation — always check thevalidfield.
Project status and readiness surfaces summarize the latest multi-shot-prompt artifact with preset, validity, shot count, issue count, generation time, and storyboard source metadata. Invalid multi-shot artifacts are warnings, not hard readiness blockers, because the artifact is optional until a workflow explicitly chooses to render from it.
Worked example
# 0. Discover preset contracts
vclaw video multi-shot --presets
# 1. Generate a 5-shot plan (reproducible with --seed)
vclaw video multi-shot --plan --shots 5 --seed 42
# 1b. Generate a provider-shaped plan from storyboard scene 0
vclaw video multi-shot --plan --from-storyboard \
--project my-project --scene 0 --route seedance-direct
# 2. Validate an existing prompt file — exits 0 if clean
vclaw video multi-shot --validate --file my-prompt.txt --explain-issues
# 3. Validate from stdin
cat my-prompt.txt | vclaw video multi-shot --validate
# 4. Apply conservative deterministic fixes
vclaw video multi-shot --fix --file my-prompt.txt --location "Tokyo alley" --time "night"
# 5. Author and validate via Gemini (requires GEMINI_API_KEYS)
vclaw video multi-shot --auto \
--image /path/to/ref.png \
--location "Tokyo back alley" \
--time "night" \
--retry-invalid 2 \
--project my-project
# 5b. Author from storyboard scene context and persist source metadata
vclaw video multi-shot --auto \
--image /path/to/ref.png \
--from-storyboard \
--project my-project \
--scene 0 \
--provider veo
# 6. Print only the raw prompt body (no JSON wrapper)
vclaw video multi-shot --auto --image /path/to/ref.png \
--location "Tokyo back alley" --time "night" --rawTokyo-alley example (5-shot, 15 s, cinematic-15s preset):
[00:00 - 00:04] Wide, 24mm, low angle, tracking — a man walks through a Tokyo alley.
[00:04 - 00:07] Medium, 50mm, eye-level, handheld — he moves between food stalls.
[00:07 - 00:09] Close-up, 85mm, high angle, static — his hand brushes a lantern.
[00:09 - 00:12] Wide, 35mm, Dutch angle, push-in — he emerges into a broad street.
[00:12 - 00:15] Medium close-up, 50mm, low angle, pull-out — he looks up at a sign.
Location: Narrow Tokyo alley, night.
Style: Cool shadows, natural skin tones. IMAX-scale composition, deep focus, practical lighting. High contrast, grounded realism. In the style of a Christopher Nolan movie.
Audio: Diegetic sound only — natural ambience, environmental foley, and subject-driven sound.Validation rules enforced by --validate / --auto:
- Timecodes must start at
00:00, be contiguous (no gaps), and total exactly--total-seconds. - Each shot duration must be within
[minShotSeconds, maxShotSeconds](default 2–5 s). - No camera parameter (shot size, lens, angle, movement) may repeat in consecutive shots.
- Prompt must not exceed
--max-chars. - A
Location:/Style:/Audio:metadata block must be present.
Full framework rules and the variation guide: vclaw video prompt-lib-show --name multi-shot-framework.
Director blueprint
vclaw video director-blueprint --project <slug> (--from-json <path> [--write] | --show) [--root <path>]The director layer ABOVE filmmaking-prompts. A Project Blueprint locks the project's visual identity, master color system, lighting grammar, per-character blueprint (silhouette + palette + voice + power/vulnerability/signature camera framing), environment blueprint (with the 5-sensory-words rule), the project camera bible (dominant + forbidden movements + the one rule the camera must never break), and performance rules. It is distinct from the story bible (continuity: cast/props/timeline) — this is the visual direction bible.
Authoring is a creative task handled by the ai-director skill, which emits a project-blueprint.json; this command only validates + persists it (--from-json … --write → artifacts/project-blueprint.json, history-tracked) or prints the stored one (--show). Validation is lenient on sub-fields but strict on the eight required sections (one listing error). Once persisted, filmmaking-prompts auto-reads it and appends a prose DIRECTOR — … addendum to every scene packet plus a forbidden-camera-movement issue per banned move — no extra flag needed. See docs/DIRECTOR_BLUEPRINT.md.
Brand definition
vclaw video brand-definition --project <slug> (--from-json <path> [--write] | --show) [--root <path>]The locked brand system for a project: brand name, positioning statement, taglines (functional/emotional/community), voice rules, a 6-color hex palette (every color carries a prompt-safe name), typography hierarchy, a 12-week theme map, and the vision-verified master asset. It layers with its neighbors: brand-dna.json (brand-extract) is extraction evidence, the brand definition is the locked brand decision, and project-blueprint.json (director-blueprint) is per-project visual direction — none replaces another.
Authoring is a creative task handled by the brand-agency skill, which emits a brand-definition.json; this command only validates + persists it (--from-json … --write → artifacts/brand-definition.json, history-tracked) or prints the stored one (--show). Validation is strict on the required sections and on palette hex (#RRGGBB), lenient on other sub-fields, and reports every problem in one error. Once persisted, filmmaking-prompts auto-reads it and appends a compact prose BRAND — Wordmark: …. Palette: …. Voice: …. line to every scene packet (palette colors render by their authored names, never hex) — no extra flag needed; no artifact → byte-identical legacy output. See docs/BRAND_AGENCY.md.
Filmmaking prompt packets
vclaw video filmmaking-prompts --project <slug> [--root <path>] [--duration <seconds>] [--panels 9|12|15|20] [--detail terse|standard|rich] [--register prose|numeric] [--storyboard-grid <path>] [--category <id>] [--genre live-action|pixar|anime|noir|influencer|action|music-video] [--aspect-ratio 16:9|9:16] [--phase storyboard|video] [--realism] [--no-realism] [--dialogue "<speaker>: <line> [emotion] [|| <speaker>: <line> [emotion]]"] [--emotion-cues] [--no-faces] [--write]Photorealism is the universal default — dial down by exception (Joey 2.0: "Photoreal is the universal default"). With zero flags and no project cinema-profile, a project resolves the full detailed treatment: rich detail, capture-realism on, and the prose cinematography register (behaviour-not- numbers physical wording, no Kelvin / key-angle / ratio numerals). Dial it down per-call with --detail, --register numeric, or --no-realism, or persist a project-wide reduction with vclaw video cinema-profile (below). Precedence is CLI flag > project.cinemaProfile > genre default > the photoreal hard default; the influencer/ugc genres default to a phone capture register.
Generates the first-class prompt packet layer derived from the ai-filmmaking workflow. This command is deterministic: it reads existing project artifacts and writes no model output unless --write is provided.
--genre is a swappable style parameter (the skill is genre-agnostic): it sets the character-sheet STYLE block, the storyboard grid style descriptors, and the Seedance FORMAT tone, and selects the annotation third line (MOOD by default, VOICE for influencer/vlog, STYLE for action/martial-arts). Aliases like photoreal→live-action, 3d→pixar, vlog→influencer resolve automatically; an unknown value passes through as a free-form descriptor. --aspect-ratio (default 16:9; use 9:16 for vertical/social) is stated in every template and every shot. --no-faces renders the storyboard grid in a silhouette / no-frontal-face register so it survives real-person content filters when used as a provider reference_image. --detail terse|standard|rich (default standard) sets cinematography language density: terse/standard emit today's phrasing unchanged, while rich appends a quantified suffix (lens mm, Kelvin + key-angle, color-grade hue°/sat%, audio dB hierarchy, move velocity in ft/s) from the shared src/video/cinematography.ts emitters. --phase storyboard|video gates which slice is returned: storyboard returns the storyboard/camera-language portion only (video seedancePackets gated to []) for the lock-the-grid step, while video and the default (omitted) return the full packet. --category <id> selects the category descriptor (character vs product path); unknown ids fail fast.
--dialogue "<speaker>: <line> [emotion] [|| <speaker>: <line> [emotion]]" weaves spoken dialogue into every Seedance packet using the same notation as vclaw video multi-shot --dialogue (the ai-filmmaking "Dialog scenes" rule: a second speaker always renders as replies:, which signals consecutive-order speech so the speakers don't collapse into each other). The text-driven variant carries it on the opening FRAME MAP beat; the grid-reference and character-sheets-plus-storyboard-grid variants carry it on the Storyline: line. A speaker whose name matches a stored character is emitted as that character's visual descriptor, never the proper name. --emotion-cues rewrites a trailing named [emotion] per speaker into physical-cue descriptors (same map as multi-shot --emotion-cues). Both default off — omitting them keeps the output byte-identical.
Joey cinematic flags
The photoreal default (rich + realism + prose) is now the zero-flag output of filmmaking-prompts; these flags tune or dial it down. vclaw video cinema-profile adds one new subcommand, so the vclaw schema --json command count moved from 82 to 83.
filmmaking-prompts:
--register prose|numeric— prose (Joey behaviour wording, no colour-math numerals) vs numeric (Kelvin / key-angle / ratio) cinematography register. Resolved defaultprose.--no-realism— dial the capture-realism block OFF (recovers the lean register even though the resolved default has it on).--sheet 8-shot|6-panel— character-sheet layout.8-shot(default) is the four-column / eight-shot sheet;6-panelemits the compact 3-column × 2-row mid-gray sheet (characterSheetSixPanelPrompt).--realism— the keystone anti-plasticcaptureRealismBlock(per-zone specular kill, subsurface scattering, strand hair, contrast curve, volumetric haze, flattering-realism ceiling, film grain) on the rich-detail Style line. On by default; pass it explicitly to tune--wet/--haze.--wet— add the moisture-matte clause (moistureMatteClause) to the realism block.--haze thin|light|heavy— volumetric-haze density (volumetricHaze) inside the realism block (defaultlight).--background mid-gray|white|black— append a backdrop-plate clause (backgroundPlate) to the storyboard-grid Style line. Mid-gray is the locked character-work default; white/black are explicit opt-ins.--lighting <id>/--grade <id>— swap the lighting / color-grade register in the rich-detail cinematography suffix (e.g.--lighting night-fire,--grade bleach-bypass). Defaultneutral-studio/teal-orange.
Project cinema-profile
vclaw video cinema-profile persists a project-level look profile onto project.json so every later filmmaking-prompts run inherits it (the dial-down-by-exception path). Each flag is optional; at least one is required.
vclaw video cinema-profile --project <slug> [--detail terse|standard|rich] [--register prose|numeric] [--realism on|off] [--no-realism] [--haze thin|light|heavy] [--capture cinema|phone] [--root <path>]
# dial a project down to a lean, numeric, no-realism register
vclaw video cinema-profile --project dhuaan --detail standard --register numeric --no-realism
# pin a UGC project to the phone capture register
vclaw video cinema-profile --project promo --capture phonemulti-shot:
--genre <id>— resolve the preset's Style line viaresolveStyleLine(music-video,action,anime,noir,influencer,pixar). Unknown/absent genre falls back to the cinematic Nolan default. The resolved style line flows into the plan JSON and theseedance-paragraph/per-shotrendered formats.
Trigger-word map (operator phrasing → emitter):
| You say… | Flag / emitter |
|---|---|
| "mid-gray" / "neutral backdrop" | --background mid-gray → backgroundPlate |
| "add haze" / "atmosphere" | --haze → volumetricHaze |
| "anti-plastic" / "not AI-looking" | --realism → captureRealismBlock |
| "wet" / "rain-soaked" / "moisture" | --wet → moistureMatteClause |
| "bleach-bypass" / "lifted blacks" | --grade bleach-bypass → lift/gamma/gain |
| "no on-screen text" | Last Frame suppression (10-block Seedance packet) |
| "music video" / "beat-synced" | --genre music-video → resolveStyleLine + musicSyncLine |
Additional Joey-adaptation surfaces wired in earlier phases: the 10-block Seedance master-prompt is the default seedancePackets format; the negative-direction lint warns on tempo negation (use positive phrasing); outfit-swap / two-step outfit-build prompt emitters; the assemble post-production helpers (cut-at-3s tail trim, letterbox normalization, gated Topaz upscale); and the photoreal-face guard that keeps real-person face refs off the seedance-direct route.
The packet includes:
characterSheetPrompts[]— 8-view character reference sheet prompts. When a character already has reference assets, the prompt uses reference-image mode and avoids re-describing the image; otherwise it uses a concise description. Descriptions over 60 words warn; over 100 words are flagged as an error (the skill's bloat/scene-contamination failure threshold).storyboardGridPrompt— a multi-panel cinematic storyboard grid prompt.--panels(9/12/15/20, default 15) sets the adaptive grid layout (3×3 / 3×4 / 3×5 / 4×5, transposed for vertical--aspect-ratio), each panel carries a per-panel timecode and a CAM / MOVE / (MOOD|VOICE|STYLE) production-note strip, and beats follow a three-act progression (setup → inciting → rising → climax → denouement).rows/colsare recorded on the prompt for the deterministicstoryboard-gridrenderer.referenceMap[]— stable@image1,@image2, ... slots for character sheets, storyboard grid, and per-scene start frames.seedancePackets[]— per-scene Seedance prompt packets. If character sheets and a storyboard grid are available, the packet uses the higher-fidelity character-sheets-plus-storyboard-grid variant; otherwise it falls back toward grid-only or text-driven prompting.issues[]— prompt-authoring warnings such as missing character descriptions, pending storyboard-grid images, or the defaultNO MUSICpolicy.
By default Seedance packets use 15 seconds, matching the ai-filmmaking rule that Seedance 2.0 generations should use the full available runtime unless the operator explicitly requests a shorter duration.
Use --storyboard-grid <path> after the 9-panel board image has been generated from storyboardGridPrompt.promptText. That path marks the storyboard-grid slot as ready, removes the pending-grid warning, and makes the grid eligible for Seedance execution. Without it, the slot remains reserved but pending.
To generate a deterministic local review board from the packet panels:
vclaw video storyboard-grid \
--project 2026-05-27_dhuaan-music-video \
--root /path/to/video-workspaceThis writes projects/<slug>/assets/storyboard-grid.png, updates the storyboard-grid slot in filmmaking-prompts.json to ready, removes the pending-grid warnings, and snapshots the updated artifact. The rendered board is not a replacement for an image-model-generated cinematic grid; it is the reviewable production-board fallback and a stable attachment point for the Seedance reference workflow.
Brand DNA ingest (brand-extract + brief --from-brand-dna)
vclaw video brand-extract --project <slug> --url <website> [--root <path>] [--gemini-endpoint <url>]
vclaw video brief --project <slug> --from-brand-dna # seed the brief from brand-dna.jsonbrand-extract turns a client website into a machine-readable brand DNA artifact — the only LLM step in the brief→storyboard chain, isolated in its own stage so downstream stages stay deterministic. It:
- scrapes the page with plain
fetch+ regex (no headless browser, no new deps), - computes the colour palette deterministically from the page's colours (drops white/black/greys, frequency-ranks: top-3 primary / next-5 secondary),
- runs one strict-JSON Gemini pass (via the shared
GEMINI_API_KEYSkey-pool;VCLAW_GEMINI_API_ENDPOINT/--gemini-endpointoverride the endpoint) for the brand-voice / audience / messaging fields, then merges the deterministic palette over the model's guess, - writes
projects/<slug>/artifacts/brand-dna.json(schemaschemas/video/artifacts/brand-dna.schema.json: brandName, industry, tagline, valueProposition, toneOfVoice[], brandPersonality[], targetAudience, keyMessages[], primaryColors[], secondaryColors[], fonts[], logoUrl, imageryStyle, layoutStyle).
Content-filter rule: the artifact records logo URL / colours / text only — scraped photoreal faces are never recorded or passed downstream as reference images (they trip the ARK/Seedance real-person filter and don't lock identity).
vclaw video brief --from-brand-dna is opt-in (off by default → brief output is byte-identical to before). When set, it reads brand-dna.json, fills --title←brandName and --intent←valueProposition only where you omit them (explicit flags always win), and parks the richer brand fields under brief.metadata.brandDna for later stages. If the artifact is absent it errors — no silent fallback. The vclaw studio --goal brand-campaign recipe chains these two commands (see docs/STUDIO.md).
Seedance Asset Library (character consistency)
vclaw video seedance-register-assets --project <slug> --character <name>:<imageUrl> [--character ...] [--group <name>] [--root <path>]Registers character reference images as xskill Asset Library avatars and returns their Asset:// URIs — the official ark/seedance-2.0 mechanism for locking character identity across shots. Passing raw photoreal image URLs in reference_images trips the "real person" content filter and does not lock identity; managed assets pass the filter and lock the character (validated 2026-05-29: identical to the proven endpoint ep-…).
- Each
--characteris<name>:<publicImageUrl>(the image must be a public http(s) URL).--groupdefaults to<slug>-cast. - Requires
SUTUI_API_KEYin the environment. - Ensures the Asset group, creates each asset, waits for it to sync to the international Ark profile (
sync_status: active), and writesprojects/<slug>/artifacts/seedance-assets.json(name →Asset://URI). - Feed the resulting
Asset://URIs into execution as scene reference paths —native-seedance.tsalready routesAsset://references intoreference_imagesonark/seedance-2.0.
End-to-end identity flow (seedance-direct)
The seedance-assets.json artifact closes the loop so identity is locked automatically at execution time, without hand-editing scene reference paths:
- Register —
vclaw video seedance-register-assetsregisters each character image as a managed Asset Library avatar and writesprojects/<slug>/artifacts/seedance-assets.json. Its canonical contract isschemas/video/artifacts/seedance-assets.schema.json({ schemaVersion: 1, projectSlug, groupName, generatedAt, assets: [{ name, assetId, assetUri, intlAssetUri }] }). - Resolve — on the
seedance-directroute only,buildExecutionPayload(src/video/execution-runtime.ts) reads that artifact viareadSeedanceAssets(workspaceRoot, slug)and auto-resolves each scene'sreferencePathsby matching the scene'scharactersnames → theirAsset://URIs. A project withoutseedance-assets.jsonbehaves exactly as before (no auto-resolution). - Budget cap — references are capped at ≤9 image / ≤3 video / ≤3 audio per submission.
assertReferenceBudgetis preflighted across the whole payload insubmitSeedanceDirectNativebefore any provider submit, so an over-budget run fails fast with no partial submission.
Characters are matched by name (the scene's characters entries), but prompts should still describe characters by visual descriptor, not proper name — names do not survive across generations; the Asset Library avatar is what locks identity.
Example:
vclaw video filmmaking-prompts \
--project 2026-05-27_dhuaan-music-video \
--root /path/to/video-workspace \
--storyboard-grid projects/2026-05-27_dhuaan-music-video/assets/storyboard-grid.png \
--writeWith --write, the packet is saved to projects/<slug>/artifacts/filmmaking-prompts.json and snapshotted in artifact history. This artifact is intended to feed the preview portal and Seedance execution layer so the operator can inspect exactly which prompt variant, reference slots, duration, and start frames are being used.
During execution, videoclaw only consumes Seedance packets whose references are all marked ready and have concrete paths. Ready packets override the scene animation prompt, duration, and reference list; pending packets are ignored and execution falls back to the normal storyboard plus asset manifest inputs. This prevents incomplete prompts such as @image3 storyboard-grid references from being submitted before the matching image exists.
Google Flow Characters & Voices (veo-useapi)
useapi.net's Google Flow v1 API exposes reusable Characters (locked identity + optional bundled voice) and custom Voices, scriptable end-to-end. This mirrors the Seedance Asset Library pattern for the veo-useapi route.
vclaw video flow-register-characters --project <slug> --input <json-path> [--root <path>]
vclaw video flow-register-voices --project <slug> --input <json-path> [--root <path>]
vclaw video flow-r2v --prompt "<text>" --character <name|ref> [--character ...] --out <path> [--project <slug>] [--root <path>] [--duration 4|6|8|10] [--aspect landscape|portrait] [--keep-music] [--allow-reverb] [--retries <n>] [--cooldown <sec>] [--dry-run]Requires USEAPI_API_TOKEN + USEAPI_ACCOUNT_EMAIL.
Native character-ad scene render (flow-r2v)
flow-r2v renders ONE Google Flow Reference-to-Video (R2V) scene straight from saved Flow characters — the native character-ad workflow. Register the person(s) and the product once with flow-register-characters, then each --character (a friendly name resolved via artifacts/flow-characters.json when --project is set, or a raw character ref) maps to character_1..7 so a single scene locks both the person and the product. Dialogue lives inline in --prompt and Veo generates the voice + lip-sync natively. It uses veo-3.1-fast (R2V; no startImage — the Veo 3.1 R2V lane clears photoreal human faces, live-proven).
By default the dry-voice (close-mic, no echo/reverb) and no-baked-music directives are appended to the prompt so a music bed added in post sits cleanly under the native voice without clashing — opt out with --keep-music / --allow-reverb. A 403 reCAPTCHA burst-throttle is cooled-down-and-retried (--retries, default 2; --cooldown seconds, default 300). --dry-run prints the composed request (resolved refs + hygiened prompt) without spending.
# lock Asha + the candle, render the hook scene with native voice
vclaw video flow-r2v --project dhuaan-candle \
--prompt 'Asha looks to camera and says: "A candle should fill the room. Most do not."' \
--character Asha --character DhuaanMaster --out outputs/ad1-s1.mp4Characters — input is a JSON array of { name, images:[path|mediaId, …], voice?, personalityNotes? } (1–2 images each; voice is a system preset like "Charon" or a registered voice ref). Each image is uploaded, then bundled into a saved character via POST /google-flow/characters. Writes projects/<slug>/artifacts/flow-characters.json ({ schemaVersion: 1, projectSlug, generatedAt, characters: [{ name, entityId, characterRef, voice }] }, schema schemas/video/artifacts/flow-characters.schema.json).
Voices — input is a JSON array of { name, basePreset, dialog, voicePerformance }. Writes artifacts/flow-voices.json.
End-to-end identity flow (veo-useapi)
- Register —
flow-register-characterssaves each character and writesflow-characters.json. - Resolve — on the
veo-useapiroute only,buildExecutionPayloadreads it viareadFlowCharacters(workspaceRoot, slug)and resolves each scene'scharactersnames → their character refs intotask.characterRefs. A project withoutflow-characters.jsonbehaves exactly as before. - Submit —
native-veo.tspassescharacterRefstoflow.tsas repeated--characterflags (Flow v1character_1..7), routing to R2V entity mode with the bundled voice.
⚠️ Moderation:
character_*routes through R2V, so realistic human faces are rejected by Google's real-person-reference filter (PUBLIC_ERROR_UNSAFE_GENERATION/INPUT_OTHER). Use Characters for stylized / mascot identities (proven live with a robot mascot). For photoreal humans, use the Veo-I2V path (--scene-first-frame/ startImage), which is a more permissive filter and also carries native voice.
API quirks hardcoded around (the HTML docs are wrong on these): POST /charactersrejects an email body field (account = token); POST /voices requires it.
Google Flow inline @-markers (veo-useapi)
useapi.net's Google Flow v1 API (blog 260609) accepts inline @-mention markers in prompt text that anchor a body-slot reference to a position in the prompt (tighter compositional control + identity without textual description):
| Marker | Index range | Endpoint |
|---|---|---|
@character_N | 1–7 | POST /videos and POST /images |
@referenceImage_N | 1–7 | POST /videos |
@referenceAudio_N | 1–5 | POST /videos |
@reference_N | 1–10 | POST /images |
- Case-insensitive (
@Character_2==@character_2) and opt-in: a body slot without a marker is always fine, but a marker without a matching body slot makes the API 400. - The marker grammar is reserved in videoclaw's prompt pipeline:
@Nametag resolution (resolveAssetTags) preserves these tokens verbatim, exactly like the@imageNpositional bindings. - veo-useapi route only — on every other route (
seedance-direct,runway-useapi,dreamina-useapi)buildExecutionPayloadstrips the marker tokens from the scene prompt and warns, so literal markers never leak to a provider that doesn't understand them. - V2V has no marker — there is deliberately no
@referenceVideo_1; video-to-video reference stays flag-only (--ref-video/referenceVideoMediaId). - The pure helper module is
src/video/flow-markers.ts(extractFlowMarkers/validateFlowVideoMarkers/validateFlowImageMarkers/stripFlowMarkers/planFlowCharacterSlots/injectFlowCharacterMarkers).
Auto-injection (@Name → @character_N) — on veo-useapi, buildExecutionPayload rewrites each @Name tag whose character has a registered Flow ref (artifacts/flow-characters.json, see flow-register-characters) into its canonical lowercase @character_N marker, and the same slot plan emits the task's characterRefs array (which becomes the repeated --character flags → character_1..7 body slots, in order):
- Ordering contract: slot order = scene cast order first (
scene.characters, today's exact order), then tag-only characters (registered names that appear only as@Nametags in the prompt, in tag scan order). - Matching semantics are split by phase. Cast-name matching is exact-case — the legacy lookup, verbatim — which is exactly why a tagless prompt yields a byte-identical payload (a cast name that only case-mismatches the registry stays unresolved, as before).
@Nametag matching is case-insensitive (@clawbotresolves to a registeredClawbot); duplicate@Namementions all resolve to the SAME@character_N(one slot — the API dedup rule). - Capped at 7 slots; registered names beyond the cap are dropped from the scene with a warning naming them.
- Hand-authored markers (
@character_2etc.) pass through verbatim and ground against the same finalcharacterRefsarray — if slot N has no entry, the vclaw-cli sidecar's pre-submit marker validation (shipped alongside this feature in thefeat/flow-markers-vclaw-clislice) fails fast before any CAPTCHA spend. - Intended behavior change: a ref-registered character's
@Nametag no longer also attaches its loose portrait image to the scene'sreferencePaths— the saved Flow character already bundles its identity images, so the portrait would only waste the shared image-reference budget. Characters WITHOUT a Flow ref keep the normal descriptor-substitution path, including portrait collection.
Direct primitives (Bun bridge)
flow.ts exposes the raw endpoints for ad-hoc use:
bun run flow.ts characters create --display-name "Clawbot" --image-ref <mediaId> [--image-ref <mediaId2>] [--voice Puck] [--personality "<notes>"]
bun run flow.ts characters list
bun run flow.ts characters delete <characterRef>
bun run flow.ts voices create --voice Charon --display-name "BuntyVoice" --dialog "Shabash!" --voice-performance "warm, excitable"
bun run flow.ts -p "He says hello" -m omni-flash --character <characterRef> # generate with a saved characteromni-flash startImage (First Frame) — now default-on
omni-flash image-to-video (startImage) is live-verified and enabled by default. VCLAW_OMNI_FIRST_FRAME=0/off is a kill-switch. Drive it through the project pipeline with vclaw video storyboard … --scene-first-frame <i>.
Prompt lint
vclaw video prompt-lint (--project <slug> | --file <path>) [flags]A pure validator over a filmmaking-prompts artifact (the JSON produced by vclaw video filmmaking-prompts --write, or any equivalent file passed with --file). It runs no providers and never spends credits — it only reads and checks. Per Seedance packet it reports:
- 10-block order — text-driven packets must carry the canonical Joey block order (
SCENE & MOOD → FRAME MAP → SUBJECT LOCK → CROSS-FRAME → MOVEMENT → LAST FRAME → WORLD PLATE → SOUND BED → CAPTURE REALISM → CAMERA CAPTURE). - Word count — warns when a packet falls outside the 280–600 words/packet window.
- Required video blocks — text-driven packets must carry
SUBJECT LOCK,CAPTURE REALISM, andCAMERA CAPTURE(error). Grid-reference variants carry the same discipline inline and are exempt. - Grid guard — when a
storyboard-gridreference is attached, the single-full-frame guard must be present, or the grid leaks as a moving 9-panel split-screen (error). - Prose-register hygiene — flags Kelvin (
5200K) and hue/angle degree (40°) numeric-register tokens in a prose-register packet (error). Pass--register numericto suppress when those numerals are intentional. - Brand / proper-name scrub — with
--cast <Name:descriptor>and/or--brand <token>, flags any packet whose text still contains a cast proper name or a brand token (error).
When the artifact carries a storyboard-grid prompt, its panels are also linted (advisory — the operator's panels are reported, never rewritten):
- Annotation slug format — CAM/MOVE/MOOD strips longer than 6 words or written as lowercase prose (they should read as 2-6 word uppercase screenplay slug lines) raise a warning.
- Framing progression — the panels should vary wide → medium → close (a grid with only one recognizable shot size warns), and the final-third climax panels should contain at least one close framing. Free-text CAM values with no recognizable shot size are ignored, never false-positived.
In --project mode, each stored character profile's identity description is additionally checked against the ai-filmmaking word budget (30-60 words is the target): 61-100 words warns, over 100 words is an error — mirroring the generation-time character-description-long check, so a pipeline can gate on the same failure after the fact. --file mode lints the artifact alone.
| Flag | Default | Notes |
|---|---|---|
--project <slug> | — | Lint projects/<slug>/artifacts/filmmaking-prompts.json. |
--file <path> | — | Lint an arbitrary artifact file instead. Exactly one of --project/--file is required. |
--root <path> | cwd | Workspace root for --project. |
--register prose|numeric | prose | Suppress the Kelvin/hue check under numeric. |
--cast <Name:descriptor> | — | Repeatable; enables the proper-name leak check. |
--brand <token> | — | Repeatable; enables the brand leak check. |
--checklist | off | Additive. Also run the 9-criterion video-prompt health checklist over each packet's prompt text. |
Output is machine-readable JSON { packets: [{ sceneIndex, issues: [...] }], grid?, characters?, ok }. The grid section ({ issues: [...] }) appears only when the artifact carries a storyboard-grid prompt; characters ([{ name, issues: [...] }]) appears only in --project mode with stored descriptions — without them the output shape is unchanged. The command exits non-zero when ok is false (any error-severity issue anywhere), so it can gate a pipeline.
With --checklist, an additional checklist array is appended to the output (the base shape is unchanged without the flag). Each entry is { sceneIndex, results: [{ criterion, pass, note? }], summary: { passed, total: 9, failures: [...] } }. The nine yes/no criteria are: explicit subject, explicit action, explicit scene/setting, camera angle, camera movement, lens/optical effects, concrete (non-vague) style, temporal/sequence cues, and audio spec. The checklist is advisory only — it does not change ok or the exit code.
# Lint a project's prompt packets
vclaw video prompt-lint --project rani-rooftop
# Lint an artifact file, enforcing brand/name scrub
vclaw video prompt-lint --file out/filmmaking-prompts.json \
--cast "Rani:a compact woman in a navy tactical vest" --brand "Nike"
# Lint plus the 9-criterion health checklist per packet
vclaw video prompt-lint --project rani-rooftop --checklistOutpaint keyframe
vclaw video outpaint-keyframe --input <path> --output <path> [--width <px>] [--height <px>] [--mask-dilation <frac>] [--fill gobananas|none] [--prompt <text>] [--size <WxH>] [--project <slug>] [--root <path>]Pad a keyframe image onto a larger target canvas (centred, letterboxed) and build an RGBA alpha inpainting mask for the new border region — the standard first step of an outpaint workflow (e.g. taking a square or portrait keyframe to a 16:9 1920×1080 frame). The pad + mask math is pure and deterministic (sharp only, no network), so the default --fill none runs entirely offline.
The mask is alpha-keyed to match the inpainting model: transparent (alpha 0) = the border region to fill, opaque (alpha 255) = the original image to preserve. --fill gobananas performs the proven upload×2 → edit-by-id flow against the go-bananas REST API: it POSTs the padded source and the alpha mask to /api/images/upload (multipart, field file), then runs a masked POST /api/edit-image with model_id: openai-gpt-image-2 (masked edits require an OpenAI model), and downloads the returned fullUrl.
| Flag | Default | Notes |
|---|---|---|
--input <path> | — | Source keyframe image (required). |
--output <path> | — | Output PNG path (required). |
--width <px> | 1920 | Target canvas width. |
--height <px> | 1080 | Target canvas height. |
--mask-dilation <frac> | 0.03 | Mask border dilation as a fraction of the smaller canvas dimension (standard inpaint overlap; the opaque keep-region shrinks inward so the fill bites into the seam). |
--fill gobananas|none | none | none writes the padded letterbox only (deterministic, offline). gobananas uploads the source + alpha mask and runs a masked gpt-image-2 edit (requires GO_BANANAS_API_KEY). |
--prompt <text> | extend-scene default | Outpaint instruction for --fill gobananas (ignored for --fill none). |
--size <WxH> | provider default | Optional gpt-image-2 output size for --fill gobananas, e.g. 1536x1024 (ignored for --fill none). |
--project <slug> / --root <path> | — / cwd | Optional context for path resolution. |
The source is scaled to fit inside the target preserving aspect ratio and is never upscaled beyond 1:1. Output is machine-readable JSON { outputPath, width, height, filled }, where filled is true only when a fill backend produced the border.
# Deterministic letterbox + mask (offline)
vclaw video outpaint-keyframe --input frame.png --output frame-1080.png
# Outpaint the border via go-bananas (needs GO_BANANAS_API_KEY)
vclaw video outpaint-keyframe --input frame.png --output frame-1080.png --fill gobananas
# Steer the outpaint with a custom prompt + pinned size
vclaw video outpaint-keyframe --input frame.png --output frame-wide.png \
--width 1536 --height 1024 --fill gobananas \
--prompt "extend the neon-lit alley, wet asphalt reflections" --size 1536x1024Overnight batch video queue
Queue many independent video jobs and run them unattended overnight. The default route is the free runway-useapi explore mode — low-res, slow "backfill draft" generation that costs no credits, so a large queue can land by morning. Target dreamina-useapi (or seedance-direct) when you want paid hi-res output instead.
Free explore-mode ceiling: 720p, ≤10s per clip. The free lane (Runway Unlimited plan, exploreMode) serves 720p max (1080p/4K are credit-mode only) and 5s or 10s durations, on a lower-priority queue (~10 min/clip, limited concurrency). Batch defaults therefore use seconds: 10 (the free ceiling) and resolution: 720p — override per job, or switch to a paid route for 1080p/longer finals.
A batch is one JSON manifest you author. It compiles into a single execution payload with N tasks and runs through the same native route transport (native-runway / native-dreamina / native-seedance) the normal execute runtime uses — there is no separate submit/poll path.
Transient retries: the native submit/poll calls on the
runway-useapi,dreamina-useapi, andseedance-directtransports are wrapped in exponential backoff (3 retries: 1s, 2s, 4s). Only transient failures are retried — network-level errors (dropped connections, timeouts) and HTTP 5xx. HTTP 4xx business errors (including Seedance content-moderation rejections) are not retried and surface immediately with their original error message.
Manifest shape
schemas/video/artifacts/batch-queue-manifest.schema.json:
{
"schemaVersion": 1,
"route": "runway-useapi",
"defaults": { "seconds": 8, "aspectRatio": "16:9", "resolution": "720p" },
"jobs": [
{ "id": "skyline", "prompt": "a neon city skyline at night, slow drift" },
{ "id": "forest", "prompt": "a quiet pine forest at dawn", "keyframe": "/refs/forest.jpg", "seconds": 10 },
{ "id": "desert", "prompt": "a desert dune ridge under hard noon sun", "aspectRatio": "9:16" }
]
}route(optional) — one ofrunway-useapi(default, free),dreamina-useapi,seedance-direct.defaults(optional) —seconds/aspectRatio/resolutionapplied to any job that omits them.- each
jobrequiresid(stable; becomes the downloaded clip filename) andprompt;keyframe(local path or public http(s) URL),characterRefs, andsecondsare optional per-job overrides.ids must be unique. characterRefs(optional, array of local paths or public http(s) URLs) — character reference images, one per character. They are delivered to the provider's reference slot (RunwayimageAssetId1..N, Dreaminaomni_N_imageRef) viareferenceRole: 'character', so a lone character sheet is never used as the video's first frame (avoids the character-grid opening). UsecharacterRefsfor identity-lock; usekeyframeonly for a genuine first-frame seed (they are mutually exclusive —characterRefswins if both are set).endKeyframe(optional, local path or public http(s) URL) — an end frame. Withkeyframeset, the clip animates fromkeyframe(first frame) toendKeyframe(last frame) via Seedance-2 keyframe interpolation (startFrameAssetId→endFrameAssetId), turning two stills into one continuous shot — ideal for combining two storyboard frames of the same subject/location into a single 10s clip. Requireskeyframe; mutually exclusive withcharacterRefs.
Commands
# 1. Submit the whole batch (free explore by default). Writes <dir>/batch-queue.json.
vclaw video batch-submit --manifest batch.json --out runs/overnight [--route runway-useapi]
# 2. Monitor on a schedule. --once does a single pass + exits (what launchd calls).
vclaw video batch-monitor --out runs/overnight --once
# 2b. Or loop foreground until everything is terminal (or --max-minutes elapses):
vclaw video batch-monitor --out runs/overnight --interval 1200 --max-minutes 600
# 3. Read-only rollup (never polls):
vclaw video batch-status --out runs/overnightbatch-submitreads the manifest, builds the payload, calls the route's native submit, and persists<dir>/batch-queue.json({ externalJobId, route, outputDir, submittedAt, jobs:[{id, sceneIndex, taskId, status}] }). Resumable on the free explore throttle (runway-useapi): the explore lane allows ~1 concurrent job, so a submit can only place some scenes before the rest hit429 canUseExploreMode. Rather than fail,batch-submitpersists each scene the moment it is accepted and reports{ submitted, pending, throttled }. Re-running it against the same--outreuses the job id and skips already-submitted scenes — it never re-fires scene 0 — so repeated calls drain the queue one slot at a time, each scene submitted exactly once. A scheduler can simply loopbatch-submituntilpendingis0.batch-monitorpolls once via the route's native transport (which downloads completed outputs to<dir>/scene-<i>.mp4), then copies each finished scene to<dir>/clips/<jobId>.mp4, updates statuses, and writes<dir>/batch-status.json.batch-statusprints the current done/pending/failed rollup without polling.
Resumable / idempotent. Re-running batch-monitor only advances pending jobs to done/failed. Jobs already done (or whose clips/<id>.mp4 already exists) short-circuit — completed clips are never re-downloaded and nothing is resubmitted. This is what makes --once safe to drive from launchd/cron on a schedule: each scheduled invocation just picks up where the last one left off.
Wedge handling (--stall-minutes / --fail-wedged, opt-in). A free-explore queue can wedge — the provider leaves a scene submitted and never returns it — which would otherwise make the monitor poll until --max-minutes. Pass --stall-minutes <n> (default 0 = off) to flag any scene still submitted more than n minutes after the batch was submitted as wedged (reported in batch-status.json and the monitor's output). Add --fail-wedged to mark those wedged scenes failed, so the queue reaches terminal and the monitor exits cleanly instead of looping; you then re-run just the wedged ids as a fresh small batch. Without --fail-wedged the scenes stay pending and are only surfaced. --stall-minutes 0 keeps the original behaviour byte-for-byte.
Auto-resubmit (--auto-resubmit / --max-resubmits <n>, opt-in). Instead of just failing wedged scenes, pass --auto-resubmit (together with --stall-minutes <n> — without a stall window it is a no-op) to re-submit each wedged scene as a fresh single-scene job, up to --max-resubmits <n> times (default 2). This is only permitted on the free runway-useapi explore route — it is refused on the paid dreamina-useapi/seedance-direct routes (a guard fires before any poll/submit, and the credit-spending path self-guards too), so auto-resubmit can never spend credits. A re-submitted scene keeps its scene-<i>.mp4 slot (first-writer-wins, so no double-download), and the monitor polls every active job id and attributes each scene to its live job. Throttle backoff applies to resubmits too.
Throttle backoff (automatic). When the explore queue is saturated (canUseExploreMode:false / HTTP 429), the monitor catches it and grows the poll interval (exponential, capped) instead of hammering; genuine errors still surface. Surfaced as throttled in batch-status.json.
Scheduling with launchd
Point a launchd agent at vclaw video batch-monitor --out <dir> --once on a 20-minute StartInterval (1200s). Each tick advances the queue and exits; when the rollup is terminal, subsequent ticks are no-ops. Finished clips collect in <dir>/clips/<jobId>.mp4, ready to use by morning.
Prompt library
prompt-lib-list and prompt-lib-show expose imported reference assets for:
- Seedance formulas
- Veo prompting guidance
- style template schema
- stage directors
- checkpoint protocol
- generation telemetry
- dialogue duration preflight
- character reference sheets
- clone-ad template workflow
- multi-shot cinematic prompt framework
Portfolio operations
vclaw video list [--root <path>]
vclaw video index [--root <path>] [--output <path>]
vclaw video metrics [--root <path>] [--mode storyboard|director]
vclaw video workload [--root <path>] [--mode storyboard|director]
vclaw video next-actions [--root <path>] [--mode storyboard|director]
vclaw video dependencies [--root <path>] [--mode storyboard|director]
vclaw video doctor-portfolio [--root <path>] [--mode storyboard|director]
vclaw video report [--root <path>] [--mode storyboard|director]
vclaw video report-snapshot [--root <path>] [--mode storyboard|director]
vclaw video report-history [--root <path>]
vclaw video report-diff [--root <path>] [--from <snapshot-path>] [--to <snapshot-path>]
vclaw video trends [--root <path>]
vclaw video export-csv [--root <path>] [--output-dir <path>] [--mode storyboard|director]Obsidian
vclaw video scaffold-obsidian-vault [--output-dir <path>]
vclaw video export-obsidian --project <slug> [--root <path>] [--output-dir <path>] [--mode storyboard|director]
vclaw video sync-obsidian [--root <path>] [--output-dir <path>] [--mode storyboard|director]Migration
vclaw video import-legacy --source <path> [--root <path>]MCP server
vclaw mcp serve starts a stdio MCP (Model Context Protocol) server exposing read-only project introspection to MCP-aware agent hosts (Claude Code, Codex, Cursor, Antigravity).
Tools exposed (all read-only)
| Tool | Input | Returns |
|---|---|---|
list_projects | { root? } | All projects in the workspace |
get_project_status | { slug, root? } | Stage + checkpoint state for one project |
get_artifacts | { slug, root? } | The project's JSON artifacts |
get_event_log | { slug, limit?, root? } | Recent events from events.jsonl |
list_provider_routes | { root? } | Provider routes + availability |
Writes go through the CLI, not MCP. Per the agent-integration research, the CLI is the deterministic action surface; MCP is for live-state queries. To create/modify a project, an agent calls vclaw video * commands directly.
Configuring an MCP client
In a Claude Code / Codex / Cursor MCP config:
{
"mcpServers": {
"videoclaw": {
"command": "vclaw",
"args": ["mcp", "serve"]
}
}
}